Integrate Document Searchability OCR with Tagging
Nutrient Document Searchability Tagging extracts metadata from PDF documents using entity extraction, taxonomy matching, and zonal text extraction. For these extraction tasks to work, the PDF documents must be text searchable. If documents are image-only, these tasks will fail because there’s no text to extract and process.
To overcome this issue, you can use Nutrient Document Searchability Tagging in conjunction with Nutrient Document Searchability OCR to ensure PDF documents are fully text searchable before Tagging attempts to process them.
Prerequisites
Before integrating Nutrient Document Searchability Tagging with OCR:
- Both Nutrient Document Searchability Tagging and OCR must be installed on the same machine.
- You need administrative access to configure both products.
- You need access to the SharePoint site collection being processed.
Integration setup
To set up the integration:
Create a library in OCR that points to the site collection, site, or library that you’re processing in Tagging and schedule it to run before Tagging.
In Tagging, go to Job > Document Settings and set Require Searchlight OCR to Yes.
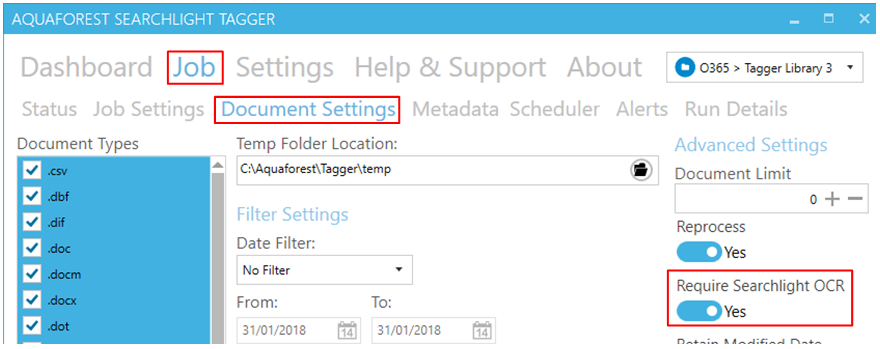
Schedule it to run after OCR. For more information, refer to the scheduler guide.
Tagging will automatically identify where OCR is installed and query its database to see the documents that have been processed by OCR. If Tagging encounters a document that hasn’t been processed by OCR, it’ll skip the document and display the following warning message in the log file.
Tagging will keep skipping the document until it’s processed by OCR.
If OCR isn’t installed, Tagging won’t work unless you set Require Searchlight OCR (see step two above) to No.