Announcing the Python SDK for Nutrient DWS Processor API
Table of contents

Today we’re launching the Python client library for the Nutrient Document Web Services (DWS) Processor API! This SDK makes document processing integration straightforward with type hints, async/await support, and workflow builder patterns.
- New Python SDK provides an ergonomic interface to the Nutrient DWS Processor API
- Type hints and async/await ensure reliable development with comprehensive error handling
- AI-native design with first-class support for popular coding assistants and Context7 integration
- Workflow builder patterns enable chainable operations for complex document processing tasks
- 100 percent API coverage with convenient methods and sensible defaults for common operations
Looking to code in JavaScript or TypeScript instead? Check out the TypeScript SDK.
Why we built these SDKs
The Nutrient DWS Processor API offers powerful document processing capabilities — converting, merging, watermarking, OCR, redaction, and digital signing. But working directly with REST APIs can be cumbersome, due to:
- Manual handling of multipart requests and binary data
- No type hints or autocompletion in your IDE
- Repetitive error handling and authentication code
- Complex workflow orchestration for multistep operations
Our new Python SDK solves these challenges by providing:
- Type hints with comprehensive Python type annotations for reliable development
- Async/await support leveraging Python’s asyncio(opens in a new tab) for efficient concurrent operations
- Simplified authentication supporting both API keys and async token providers
- Intelligent error handling with structured error types and detailed context
- Workflow builders for chaining complex document operations
- AI-native development with built-in support for popular coding tools
Key features and benefits
The Python SDK is designed to give developers a clear, consistent, and efficient way to handle complex document workflows. Here are some of the core capabilities you can rely on.
Complete API coverage
The Python SDK provides 100 percent mapping to the Nutrient DWS Processor API, with more than 35 document processing operations:
- Document conversion — PDF, PDF/A, PDF/UA, DOCX, XLSX, PPTX, PNG, JPG, WEBP, Markdown, and HTML
- Editing operations — Watermark, rotate, flatten, redact, merge, split
- Digital signing — PAdES standards-compliant signatures
- Data extraction — Text, tables, key-value pairs, structured content
- OCR processing — Multi-language image and scan recognition
- Security features — Redaction presets, password protection, permissions
- Optimization — Compress files without quality loss
Type hints and developer experience
The Python SDK provides comprehensive type annotations that give you confidence in your code and enable excellent IDE support:
import asynciofrom nutrient_dws import NutrientClient
client = NutrientClient(api_key='your_api_key')
# Type-hinted method calls with full IDE support.async def main(): pdf_result = await client.convert('document.docx', 'pdf') text_result = await client.extract_text('scanned.pdf')
# Access typed results. pdf_buffer = pdf_result['buffer'] print(text_result['data']['pages'][0]['plainText'])
asyncio.run(main())Convenience methods with smart defaults
While you can access the full power of the API, we’ve also provided convenience methods for common operations:
# Simple conversion with smart defaults.pdf = await client.convert('document.docx', 'pdf')
# Or customize every aspect via workflow.pdf = await (client .workflow() .add_file_part('document.docx') .output_pdfa({ 'conformance': 'pdfa-2b', 'optimize': { 'mrcCompression': True, 'imageOptimizationQuality': 3 } }) .execute())Workflow builder pattern
For complex document processing tasks, the Python SDK offers a fluent workflow builder that leverages async/await for efficient processing:
from nutrient_dws.builder.constant import BuildActions
result = await (client .workflow() # Stage 1: Combine multiple documents into one workflow. .add_file_part('contract.pdf') .add_file_part('appendix.pdf')
# Stage 2: Apply actions — process the combined documents. .apply_action(BuildActions.watermark_text('CONFIDENTIAL', { 'opacity': 0.5, 'fontSize': 48 })) .apply_action(BuildActions.create_redactions_preset('email-address'))
# Stage 3: Set output format — specify final document properties. .output_pdf({ 'optimize': { 'mrcCompression': True, 'imageOptimizationQuality': 2 } })
# Stage 4: Execute — run the entire workflow and get results. .execute())AI-native development experience
This Python SDK is designed to work in collaboration with AI coding assistants. We provide first-class support for popular AI tools, including Claude Code, GitHub Copilot, JetBrains Junie, Cursor, and Windsurf.
After installation, run one command to download the complete package documentation directly to your AI agent’s rule sets:
dws-add-claude-code-ruledws-add-github-copilot-ruledws-add-junie-ruledws-add-cursor-ruledws-add-windsurf-ruleWhat this means for your development experience:
- Improved AI assistance with comprehensive SDK documentation
- Reduced hallucination when generating code
- Built-in support for common questions
- Clean integration that doesn’t interfere with other tools
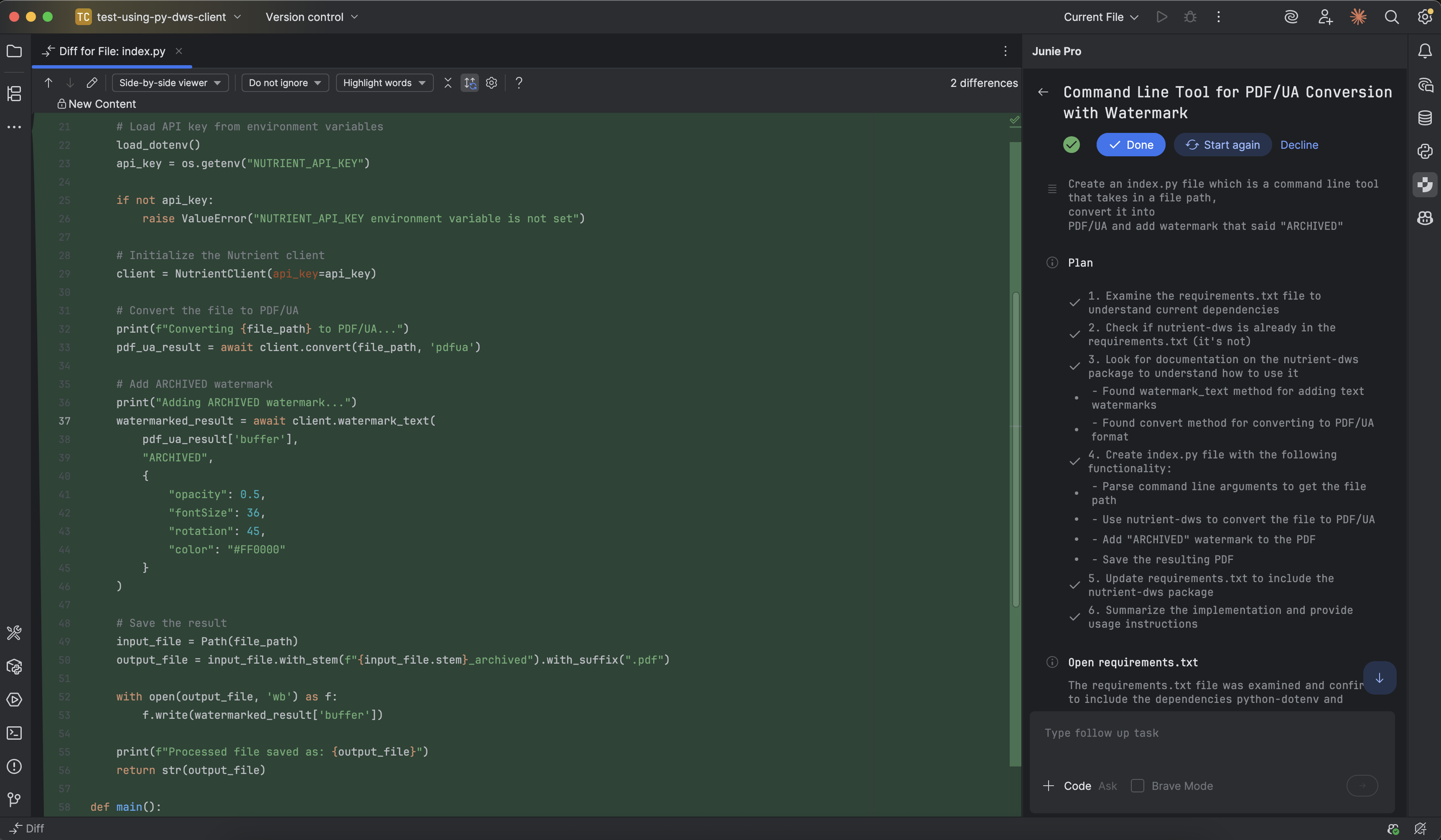
Using JetBrains Junie as an example, after installing our documentation rules, Junie could fluently generate code based on coding tasks.
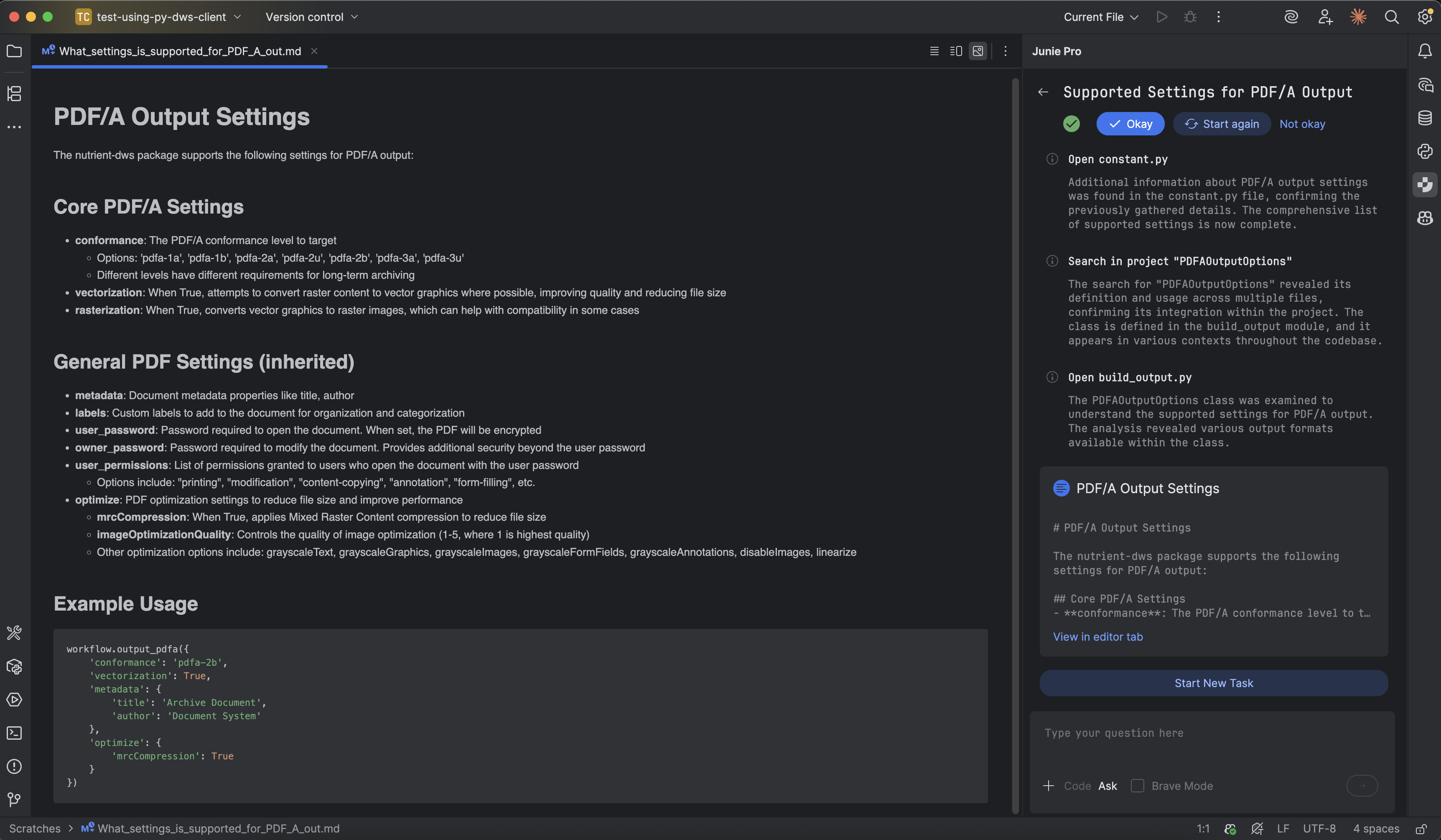
Junie can also answer detailed questions about the package documentation, serving as a first line of support for developers.
Context7 MCP Server integration
Beyond individual AI assistants, we’re also making our documentation available through Context7(opens in a new tab) — a Model Context Protocol (MCP) server that provides AI agents access to documentation for popular packages like React, Next.js, and Tailwind CSS.
Our Python package is available on Context7:
This allows any MCP-compatible AI agent to browse and fetch our documentation on demand, providing even more flexible integration options.
Get started today
Before getting started, you’ll need:
- A Nutrient DWS Processor API key
- Python 3.10 or higher
Don’t have a Nutrient DWS API key yet? Sign up for free(opens in a new tab) and get 200 free credits monthly to get started with watermark-free document processing.
Python SDK
Install via pip:
pip install nutrient-dwsBasic usage:
import asynciofrom nutrient_dws import NutrientClient
async def main(): client = NutrientClient(api_key='your_api_key')
# Convert documents. pdf_result = await client.convert('presentation.pptx', 'pdf')
# Access the converted PDF buffer. pdf_buffer = pdf_result['buffer'] with open('presentation.pdf', 'wb') as f: f.write(pdf_buffer)
# Merge multiple PDFs. merged = await client.merge(['doc1.pdf', 'doc2.pdf'])
# Add watermarks. watermarked = await client.watermark_text('document.pdf', 'DRAFT')
# Extract data. extracted_text = await client.extract_text('scanned.pdf')
# Access extracted text. text_content = extracted_text['data']['pages'][0]['plainText'] print(text_content)
asyncio.run(main())Real-world use cases
The following sections outline some powerful workflows you can build with the Python SDK.
Document automation pipeline
from nutrient_dws.builder.constant import BuildActions
# Process contracts end to end.async def process_contract(contract_file: str): # Stage 1: Combine, watermark, and archive documents in a single workflow. combined = await (client .workflow() .add_file_part(contract_file) .add_file_part('terms-and-conditions.pdf') .apply_action(BuildActions.watermark_text('CONFIDENTIAL')) .output_pdfa({ 'conformance': 'pdfa-2b', 'optimize': {'mrcCompression': True} }) .execute())
# Stage 2: Apply a digital signature for legal compliance. signed = await client.sign(combined['output']['buffer'], { 'signatureType': 'cades', 'cadesLevel': 'b-lt' })
return signedBatch document processing
async def process_invoices(invoice_files: list[str]): """Extract data from multiple invoices and compile results""" import asyncio
async def process_single_invoice(invoice_file: str): # OCR the invoice if it's a scanned image. ocr_result = await client.ocr(invoice_file, 'english')
# Extract key-value pairs from the OCR result. kvp_result = await client.extract_key_value_pairs(ocr_result['buffer'])
return { 'file': invoice_file, 'data': kvp_result['data'] }
# Process invoices concurrently using `asyncio.gather`. results = await asyncio.gather( *[process_single_invoice(file) for file in invoice_files] )
return resultsAdvanced redaction workflow
from nutrient_dws.builder.constant import BuildActions
# Multistep redaction with different strategies.async def redact_sensitive_info(document: str): return await (client .workflow() .add_file_part(document) .apply_actions([ # Strategy 1: Target specific known content with exact text matching. BuildActions.create_redactions_text('Account Number: 12345'),
# Strategy 2: Use built-in patterns for common sensitive data types. BuildActions.create_redactions_preset('email-address'), BuildActions.create_redactions_preset('credit-card-number'),
# Permanently remove all marked content. BuildActions.apply_redactions() ]) .output_pdf() .execute())We want your feedback
This Python SDK represents a significant step forward in making document processing more accessible to Python developers. We’d love to hear about your use cases, feature requests, and feedback:
- Python SDK — GitHub issues(opens in a new tab)
- General questions — Contact our team
Try it out and let us know what you think — we’re excited to see what you’ll build!