Nutrient Document Searchability release notes
This page documents the release history of Nutrient Document Searchability. Each version includes enhancements and bug fixes to improve SharePoint integration, OCR capabilities, and document processing.
Version 2.8.2508.22
Enhancements
[PS-320] Implemented MSAL for SharePoint authentication
Document Searchability now authenticates SharePoint using the Microsoft Authentication Library (MSAL) instead of the deprecated Azure Active Directory Authentication Library (ADAL). MSAL enhances security and token management capabilities.
Modern authentication has been fully migrated to MSAL, and no changes are required for customers currently using modern authentication.
For more information, refer to our announcement post.
Version 2.6.2403.06
Enhancements
[PS-286] Implemented new option of enumerating documents
Searchlight now has a new way of enumerating documents by querying already crawled data in SharePoint. This is controlled by the “useCrawledData”, “dateInterval”, and “dateIntervalComparisonOperator” settings in the Searchlight.config file. Contact us for more information on how to use this new feature.
Bug fixes
- [SDK-210] Document Searchability re-OCRs visible text when Remove Hidden Text is set to Yes.
- [PS-285] Upgrading the database from version 2.1 to 2.6 sometimes fails.
- [PS-287] Links in the UI point to invalid URLs.
Version 2.6.2308.09
Bug fixes
[SDK-199] The OCR process removes visible text from document.
Version 2.5.2304.13
Bug fixes
- [PS-274] Searchlight service not starting.
- [PS-277] Date filter settings aren’t kept on save.
Version 2.5.2301.16
Enhancements
- [PS-264] Detect digitally signed documents and create bypass/processing option.
Bug fixes
- [PS-260] Scheduler: After changing selection back from
ScheduledtoManualStart time window remains mandatory. - [PS-261] Excluded documents for SharePoint doesn’t work if the file name has a comma ”,”
Version 2.5.2206.11
Bug fixes
[PS-255] Fixes an issue where the system doesn’t send alert email.
Version 2.5.2206.08
Bug fixes
- [PS-253] Fixes an issue where if you delete a library that runs on a schedule, Searchlight still attempts to run it.
- [PS-254] Fixes an issue where the dashboard doesn’t properly display the scheduler type.
Version 2.5.2205.30
Enhancements
- [PS-57] [PS-236] Upgrades the scheduler to enable more granular scheduling options.
- [PS-243] Adds alternative web control for SharePoint web authentication.
- [PS-234] [PS-246] Adds support for SharePoint App-Only Authentication
- [PS-247] Sends successful email alert only if at least one document was successfully processed.
- [PS-249] Adds option to delete all locations from a library from the UI.
- [PS-250] Updates locations list box to display authentication type and authentication details for each location type.
Bug fixes
[PS-252] Fixes issue with deleting locations referenced in multiple Searchlight libraries.
Version 2.2.2203.08
Bug fixes
[PS-245] Fix for “Field or property IsHubSite doesn’t exist” for SharePoint On-Premises
Version 2.2.2202.02
Bug fixes
[PS-244] Enumerating site collections using tenant admin URL with Modern Authentication fails.
Version 2.2.2201.19
Enhancements
[PS-242] Added ability to enumerate OneDrive personal sites when using the “Enumerate Site Collections” feature.
Bug fixes
[PS-240] Database Manager fails to validate SharePoint credentials.
Version 2.2.2112.22
Bug fixes
[PS-239] Root SharePoint URLs aren’t processed.
Version 2.2.2111.30
Enhancements
[PS-227] Add support for SharePoint App-Only Authentication via the Searchlight.config file. Contact support@nutrient.io on how to use this new feature.
Bug fixes
- [PS-237] Delete Cert keys in “ProgramData\Microsoft\Crypto\RSA\MachineKeys” after use.
- [PS-238] Daylight saving causes jobs scheduled to run continuously to start at the wrong time.
- [SDK-181] Extended OCR engine adds multiple instances of words in the output PDF document when OCR’ing in Native mode.
Version 2.2.2110.12
Enhancements
[PS-227] Added support for interactive authentication for SharePoint Online
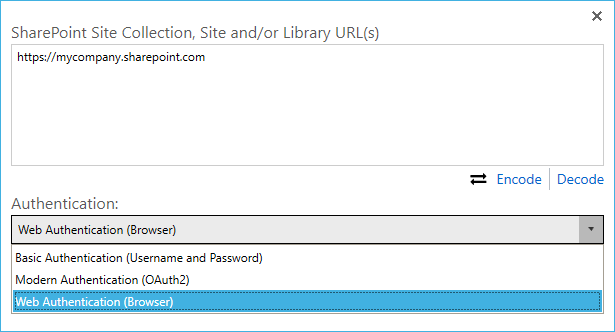
Bug fixes
- [PS-229] Location paths aren’t excluded when “Library Type” is “File System”.
- [PS-232] Attachments aren’t identified and retrieved from certain .MSG files.
Version 2.1.2105.26
Bug fixes
- [PS-223] Fixed intermittent failures when uploading very large files to SharePoint On-Premises.
- [PS-224] Fixed issue where OCR fails with a “License Error” message when running an Audit and OCR job immediately after installing Searchlight.
Version 2.1.2104.29
Enhancements
Updated Extended OCR engine to version 15.6.8.3176.
Bug fixes
[SDK-166] Fixed issue with mirroring that occurs when processing certain TIFF files.
Version 2.1.2103.30
Bug fixes
[PS-221] [SDK-168] Cores aren’t released when OCR process exits on exception or process is killed via Task Manager.
Version 2.1.2102.23
Enhancements
- [PS-218] Add EmbedFontSubset setting in the UI for the Standard OCR engine.
- [SDK-162] Better font handling and character encoding when OCRing documents
Bug fixes
- [SDK-161] Setting “Retain Creation Date” causes the Extended OCR engine to fail to generate the output PDF.
- [PS-217] Searchlight fails to process File System files with long paths.
Version 2.1
Enhancements
- This version has the new version 3.0 of the OCR engines
- [SDK-143] Add new iDRS engine in Extended OCR
- PDF/A-3a and PDF/A-3b output is now supported.
- Vietnamese and Thai language is now supported.
- [SDK-151] Add options to stop processing when page(s) fail(s) to process in Native mode. Previously, if the OCR engines failed to OCR all pages of a document in Native, the original source document was outputted. However, this made it difficult to mark and identify the document as failed. The new setting can be used to indicate to the OCR engine how to respond if there are issues processing page(s) in Native mode. The available options are:
- Do not stop processing if a page fails to process.
- Stop processing only if all pages fail to process.
- Stop processing if at least one page fails to process.
- [SDK-143] Add new iDRS engine in Extended OCR
- [PS-206] Implement a new feature that enables processing of secured PDFs. This feature is controlled by the processSecuredPdf setting in the Searchlight.config file.
Note: The service must be restarted after making the change in the Searchlight.config file.*
- [PS-208] Add the ability to enumerate and process all site collections in a Tenant in SharePoint Online when the Tenant Admin URL is entered.
- [PS-209] Implement a new command-line tool that enables users to add, update and delete locations of document libraries without the UI.
- Email alert enhancements
- [PS-205] Add “Test Email” functionality in the “Settings > Email” tab.
- [PS-213] Add support for sending emails with OAuth2 authentication.
- [PS-214] Add support to specify multiple email recipients. This can be achieved via the new Cc and Bcc fields as well as specifying multiple email addresses by separating each one with a semicolon in the “To”, “Cc” and “Bcc” fields.
Bug fixes
- [PS-211] Better handling of large files in SharePoint Online. Previous versions of Searchlight couldn’t upload the processed files if they were larger than 250 MB.
- [PS-212] When processing image files, Searchlight fails to retain the values of metadata columns if the column name contains the dash “-“ character.
Version 2.0
Upgrading from previous versions
If you are upgrading from a previous version, you will need to request a new license key from Aquaforest: sales@nutrient.io.
We highly recommend users creating a backup of their database before attempting an upgrade. The database can be found at [installation path]\data\Searchlight.db. The database can be very large, depending on the number of runs.
For detailed information on upgrading, visit our upgrade blog: http://www.aquaforest.com/wp/index.php/upgrading-aquaforest-searchlight-2/(opens in a new tab)
Enhancements
Web interface
A Searchlight 2.0 web interface has been developed for IIS, giving users more freedom to process documents the way that best suits the needs of their business. Requires certain pre-requisites and IIS to run. Contact support@nutrient.io for more information.
Azure storage
Library types now include both Azure Blob Storage and Azure File Share, so files can be downloaded from and saved to these library types.
Report, error, and archive locations
Previously, report, error and archive locations could only be set to file system locations. In Searchlight 2.0, these locations can be set to any supported library type.
Retain folder structure
When archiving or copying/moving error files, there is now the option to retain the original folder structure.
Time zones
Searchlight 2.0 now has a time zone tab (Settings > Date & Time), so users can view and select their preferred time zone.
Support for anonymous/unauthenticated SMTP servers
Email alerts can now be set up without authentication. For SMTP servers that have anonymous access enabled, this enables users to send emails without authentication details to access the server.
Customizable SharePoint queries
Retries for SharePoint queries are now only performed for specific HttpStatusCodes by default and is defined in the httpStatusCodesToRetry setting in the Searchlight.config file.
The number of times to retry and the amount of time to wait before each retry is specified in the webRequestRetries setting.
See the comments in the Searchlight.config file for more information:

*NOTE: The Searchlight service must be restarted after making the change.*
Support for ‘#’ and ‘%’ added
As Microsoft added support for ‘#’ and ‘%’ in SharePoint Online, SharePoint 2019 and OneDrive for Business, we now support the use of both characters in folder and file names.
Generate alerts when library password is incorrect
Implemented ability to generate alerts when there are one or more connection errors (SharePoint and Azure). A new setting has been added to support this feature in Alerts > Trigger.

Email ‘On Job Error’ returns error message
Emails that are sent on job error can now include the error message that is returned in the log file by using the %ERRORMESSAGE% template when defining the email message.
Replacing invalid characters
Searchlight 2.0 now interacts with many location types with different supported character rules. If a file is saved to a destination that doesn’t support characters in the filename, these will be replaced with the character defined in the replaceInvalidCharactersWith setting in the Searchlight.config file.
*NOTE: The Searchlight service must be restarted after making the change.*
Check Source File before Replacing on File System
On file system only, there is now the option to check if the source file has been changed during OCR, before it is replaced by the OCR file.
The checkSourceFileBeforeReplacingWithOcredFile setting in Searchlight.config deals with this.
*NOTE: The Searchlight service must be restarted after making the change.*
PDF pages with spaces only
There is an added option of treating PDF pages that contain only spaces as non-searchable. This can be changed via the treatPdfPagesContainingOnlySpacesAsNotSearchable setting in Searchlight.config.
*NOTE: The service must be restarted after making the change.
Enable log details to database
By default, log details are no longer saved to the database. However, this can be enabled by changing the addLogToDatabase setting in Searchlight.config.
The Searchlight service must be restarted after making the change.
Accessing servers with invalid certificates
If Searchlight tries to access a site that has an invalid SSL certificate, it will fail with an error message like “Could not establish trust relationship for the SSL/TLS secure channel.”
There are two settings in the Searchlight.config file that can be used to fix this.

- recognizedCertificateThumbprints
Use this setting to add the thumbprint/fingerprint (SHA-1) of the certificate that is causing the issue. More thumbprints can be added by separating each one with a comma. This is recommended way as it instructs Searchlight to only ignore errors of recognized certificates.
Check the Troubleshooting Guide to see how to retrieve the thumbprint or fingerprint of the certificate.
- ignoreAllCertificateErrors
Set this setting to true to ignore all errors for all certificates.
*NOTE: The Searchlight UI and service must be restarted after making the change.
Bug fixes
Duplicate locations
Two jobs aren’t allowed to have the same library path, but certain path names were treated as the same. The validation for this has been improved, and duplicate locations should no longer be possible.
Empty library tab
The Library tab will now be grayed out if no jobs are saved, as setting up a new job in this tab isn’t intended and can cause errors. New jobs should be set up via the Dashboard instead.
Braces causing errors in O365
Files with the characters ‘}’ or ‘{‘ in their name were unable to be OCRed by Searchlight in , logging an error. Files are now correctly OCRed.
Searchlight losing metadata that contains control characters
Previously, Searchlight could not carry over metadata from image files if they had control characters in them. Now, control characters are automatically removed from the metadata when copying them over to the OCR’ed PDF.
Version 1.31.181029
Enhancements
Modern authentication
Added support for modern authentication. The solution involves using Azure Active Directory App-Only authentication.
In summary, you need:
- Create a self-signed certificate
- Register a dummy Web App in Azure (no coding involved)
- Give the Web App permissions to access the SharePoint tenant
- Connect the certificate created in step 1 to the Web App
Full instructions can be found in the following link:
Arabic language
This version of Searchlight contains an updated version of the Extended OCR engine with better recognition for documents with Arabic text.
Bug fixes
MSG documents
MSGs without attachments were being copied/moved to error folder if Error Rule was set. This has now been fixed.
Archiving files
Archive files were getting overwritten when processing multiple files with the same name in different folders on the same run. As an initial fix, you can use the %GUID% template when specifying the Archive Template in the Archive Settings tab.
Long file paths
A bug was introduced that prevented files with long paths from being processed in Windows 10 and Windows Server 2016. This has now been fixed. See section Long Path Support in the Troubleshooting Guide for more information.
CSV report
When generating reports, all numbers (number of documents, searchable pages, image-only pages, etc.) are formatted such that a character is added as the thousands separator. In most cases this is the “,” character (e.g., 1,200) but if the “Date, time and number format” settings in Windows is set to Swedish for instance, the character for the thousands separator will change to “space”. Due to encoding, this was coming out as “” when opened in Excel. This has now been fixed.
TLS 1.1 and 1.2
Searchlight was unable to connect to SharePoint servers where only TLS 1.1 and/or 1.2 was enabled. The Searchlight.config file now has additional configuration options to enable the various cryptographic protocols supported by SharePoint.
Version 1.30.180530
Bug fixes
Temp folder deletion
A bug was introduced in version 1.30.180418 where the temp folder wasn’t deleted. This has now been fixed in this version.
Enhancement
Enable or disable SSL
Added a new config option to enable users to control whether they want to use SSL to send emails from Searchlight. This is controlled by the “enableSmtpSsl” setting in the Searchlight.config file.
Version 1.30.180418
Enhancements
Arabic OCR
Added an updated version of the Extended OCR engine that gives better recognition results for Arabic.
Work depth
The default value of “Work depth” in the Extended OCR engine has been set to “128” instead of “0”, which gives better OCR results for most documents.
Filter dates
Users can now select the same “From” and “To” date when filtering documents under the “Document Settings” tab.
Bug fixes
MSG attachments
If a MSG file had two different attachments but with the same name, one of them was overwritten with the other. This has now been fixed.
Also, fixed another issue where if a MSG file had a mixture of searchable and non-searchable documents, all attachments were skipped and not processed.
Copying metadata from image document to OCRed version
Metadata wasn’t being copied over from source image files to the OCRed file if:
- the source image file’s content type had a “required” column and
- the content type was the default content type in the library
OCR document with same name after deleting it
If an already processed document was deleted and a document with the same name was re-added, it wasn’t OCRed if run in the following order: Audit-only then Audit and OCR. This has been fixed.
Database upgrade
Upgrading the Searchlight database from versions prior to 1.23 to 1.30 was causing issues. This has now been fixed.
Version 1.30
Enhancements
Custom comment on a custom SharePoint column
Added a new feature that enables the addition of custom comments on another SharePoint column after a document is OCRed. However, the SharePoint column must be either of Text or Date type.

There is also the option of specifying the following templates in the check-in comment:
- %DATE% : will be replaced by the date the document OCRed
- %TIME% : will be replaced by the time the document OCRed
Enumeration progress
Added live progress on the dashboard during the enumeration stage which will give more information about what Searchlight is doing during long enumeration jobs.
SharePoint lists
The option for processing SharePoint Lists has been moved from the Searchlight.config file to the UI under Library Settings. This stops it from being a global setting affecting all document libraries defined in Searchlight and makes it specific to each document library.
Forms authentication cookie refresh
Added a new config setting to refresh forms-based authentication cookies. The default is current set to 900,000 milliseconds (15 minutes). To change the default value, update the “formsAuthCookieRefreshInterval” setting in the config file.
SharePoint request timeouts
The amount of time that a SharePoint request can execute for before timing out is now configurable via the Searchlight.config file. The default is current set to 300,000 milliseconds (5 minutes). To change the default value, update the “requestTimeout” setting in the config file.
Database journal mode
The journal mode for the SQLite database has been changed to WAL to improve concurrent read performance.
Bug fixes
Hanging
Under certain very specific circumstances update(s) to the database could hang. This should now be fixed.
Database update
There was a bug whereby a particular update operation was taking very long to complete on very large databases. This has now been fixed.
Scheduler time
If the time format on the server running Searchlight was set to 12-hour clock and the time in the Scheduler was changed manually by keyboard, it would throw an exception. This has now been fixed.
Import settings from existing document libraries
When using the “Import settings from an existing document library” feature, Aquaforest OCR settings weren’t getting imported. This has now been fixed.
Cyrillic languages
Fixed issue with OCRing Cyrillic languages with the Aquaforest OCR engine.
0KB statistics file
If the Searchlight service closes unexpectedly (e.g., by forcefully stopping the service or restarting the server), the stats.xml file could end up corrupted (0KB). This was preventing document libraries from running. This has now been fixed.
Temp files deletion in file system libraries
Searchlight wasn’t deleting temp attachments after auditing .msg files in “File System” libraries even if “deleteDocumentsAfterAudit” was set to true in Searchlight.config.
Version 1.23
Enhancements
Updated OCR engines
The version contains the latest Aquaforest and Extended OCR engines.
Arabic and Farsi OCR languages support
Two new language support has been added to the Extended OCR engine namely Arabic and Farsi. These languages are optional add-ons and require a special license. Contact support@nutrient.io for more information.
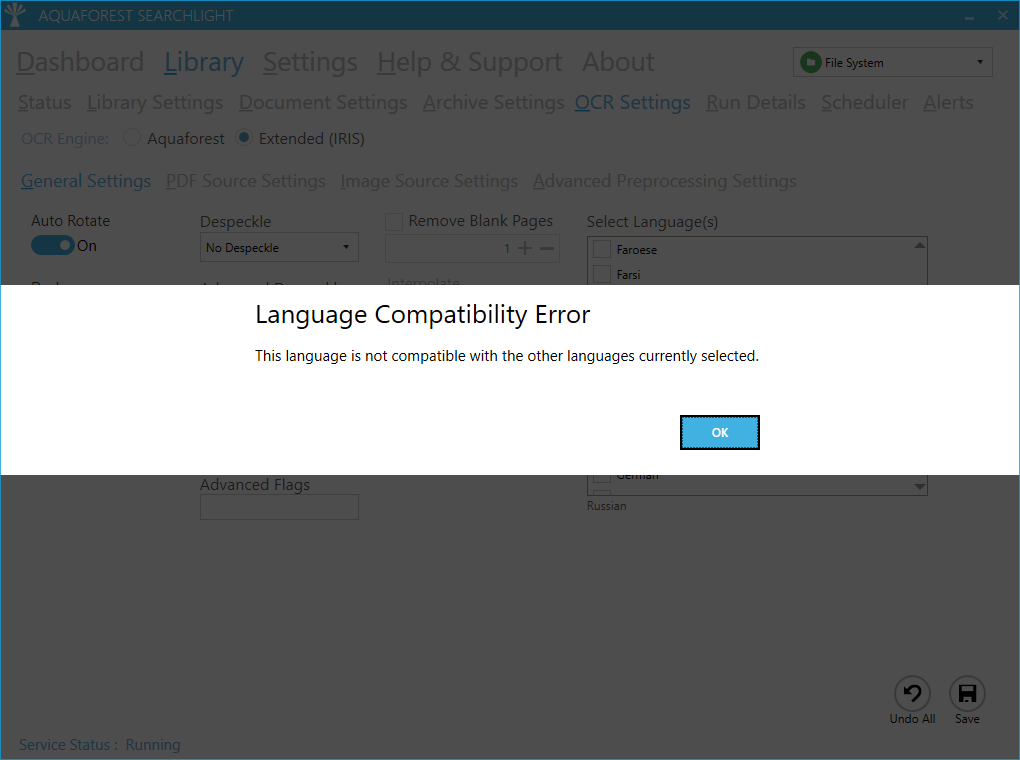
Extended OCR languages compatibility check
Extended OCR accepts up to eight recognition languages at a time. This is helpful to process mixed documents but, because of the various character sets, not all combinations are allowed. For this reason, the multiple languages support is limited to a single alphabet. For example, Russian and French can’t be mixed.
In this version, a new feature has been added to check the compatibility of selected languages when using the Extended (IRIS) OCR engine.
Added ability to process PDFs with forms
In previous versions, text contained inside PDF forms were ignored during the Audit stage thus marking PDF documents as being image-only even if they contained text. This has been fixed in this version.
Advanced prefiltering by content types and custom SharePoint columns
The advanced document pre-filtering added in version 1.22 has been further enhanced so that custom SharePoint columns can be pre-filtered.
In the previous version, only pre-filtering by document name and URL were possible.
Better support for processing multiple libraries without database locks
In previous versions, when running multiple jobs simultaneously, there were lots of database lock errors which compromised the integrity of the job as well as the database. This has now been improved, although it is still not recommended to run too many jobs simultaneously.
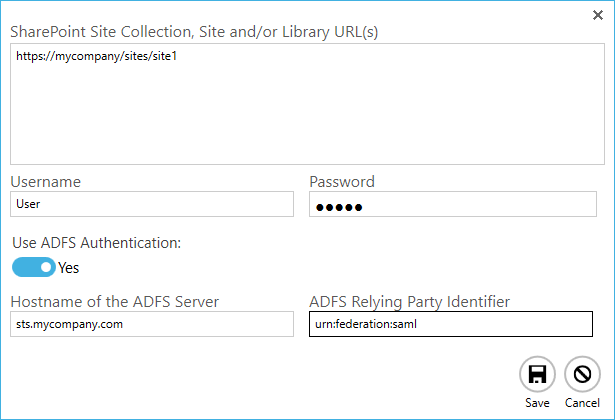
SharePoint On-Premises ADFS support
Searchlight now supports SharePoint On-Premises ADFS authentication. You will need to provide the host name of the ADFS server as well as the ADFS relying on party identifier.
SharePoint URLs auto-fix
Searchlight now has the ability to automatically format SharePoint URLs to valid form required by Searchlight. See section “4.6.2 URL format” in the Reference Guide for more information.
Added ability to import settings from existing document libraries
Settings can now be imported from existing document libraries. See section 5.3 in the Reference Guide to see how this can be achieved.
Sorting of dashboard items
Items in the dashboard can now be sorted by clicking on the column headers. The sort direction is indicated by the ‘arrow’ on the left of header title.
▲ = Ascending
▼ = Descending
![]()
![]()
Sorting items in the dashboard will also sort the document library list combo box under the Library tab.

Database cleanup tool
Running Searchlight over a long period of time can dramatically increase the database size. This can be an issue if space is limited in the server running Searchlight.
Searchlight now comes with a tool that will try to compact the database by deleting logs from previous runs and previous run history. The runs from which the logs are to be deleted can be selected either by date last run or by the Run ID.
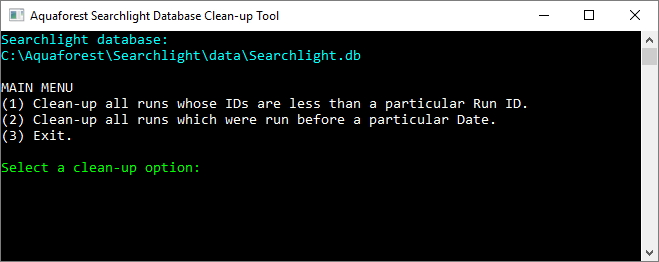
To find out the Run ID or the date a document library was last run, select a document library from the dashboard (preferably one that was run most recently) and go to the Status tab.
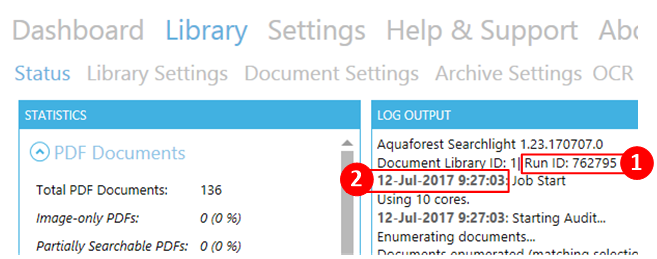
In the LOG OUTPUT section, you will be able to find the:
- Run ID
- Date the document library was run
The tool can be accessed at the following location:
“[Install location]/bin/ Aquaforest.Searchlight.DatabaseCleanup.exe”
Removed dependency on ports
Searchlight no longer requires the use of TCP ports for communication between the UI and the Searchlight service. It has been replaced by a more reliable and much faster alternative.
Changes
.NET Framework
This version of Searchlight no longer requires .NET Framework 3.5. However, it still requires .NET Framework 4.5.2
.Visual C++ Redistributable
Visual C++ Redistributable 2013 is now required instead of 2012.
Download/upload
Changed the methods used to download and upload files from/to SharePoint so as to cope with changes made by Microsoft to Office 365 (SharePoint online).
Bug fixes
SharePoint versioning
There were a number of issues with how versioning was handled by Searchlight when Retain Modified/Created Date/User settings were selected. This should now be fixed.
Passwords with spaces
In previous versions, Searchlight could not handle passwords with spaces in them. This has now been fixed.
Version 1.22
Enhancements
Advanced prefiltering
Added a new feature to pre-filter locations and documents by Regular Expressions before processing.
- Location filtering
This can be useful if you are processing a whole site collection but only want to include certain sites and libraries for processing.
For instance, you may want to only process sites and libraries containing the word “Resources” in their URL:
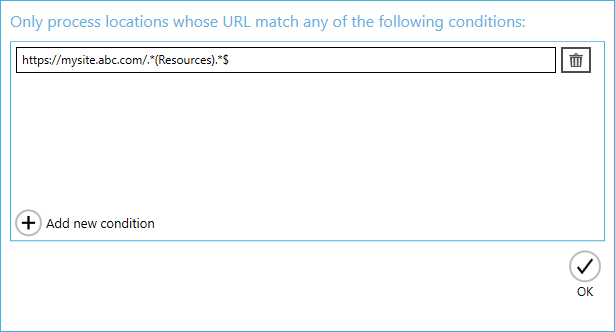
The location filters can be added through Library > Library Settings > Filter Locations by Regular Expression.
- Document filtering
This can be useful if you want to only process documents with a certain naming convention.
For instance, you may want to only process documents with the name format “ABCD-1234”:

The document filters can be added through Library > Document Settings > Filter Documents by Regular Expression.
Pause and stop during enumeration stage
The Pause and Stop (Abort) functionality can now be used during the document enumeration stage. Previously, it was only available during the Audit and the OCR stages.
Note, however, that the more cores you are using (Library > Library Settings > Cores), the longer it will take to Pause or Stop the enumeration.
Bug fixes
Remove visible text
Remove visible text wasn’t working for the Aquaforest OCR engine.
“Invalid URL” error when adding specific URLs to “Exclude Locations”
The issue occurred when adding URLs that contain spaces. This fix also addresses another issue where child URLs weren’t getting excluded if a root URL was added to the excluded locations.
Searchlight erroring out when processing .MSG files
This error occurred when a library that had .MSG files with no PDF attachments was processed. If after processing (auditing), a document was deleted from the SharePoint library and the library was run again, it would error out.
“Invalid URL” error when adding sites/site collections that have periods (.)
Searchlight could not add sites/sites collections that had periods (.) in them.
e.g. “https://test.sharepoint.com/sites/site.with.period”
Scheduler issues
When Searchlight was set to run continuously for short intervals (e.g., every 5 mins), it stopped working after 1 or 2 days even though the service was still running.
Adding O365 locations
When adding a new O365 site collection or site or document library, users were clicking on the “Find” button instead of the “Save” button.
The “Find” feature is to enumerate O365 site collections if a tenant admin URL is added. The admin URL is usually in the format: https://{mysite}-admin.microsoft.com
However, if a non-admin tenant URL is specified (i.e., normal site collection/site/document library URL) and “Find” was clicked, it was giving the impression of enumerating site collections without ever returning or giving an error message. This has now been fixed.
“Request uses too many resources” when processing very large lists
When processing lists with very large number of list items, Searchlight would fail at the enumeration stage with one of the following errors:
- The Request uses too many resources
- Too many requests
When searchlight retrieves items from SharePoint, it did so in batches of 2,000. For SharePoint Document Libraries, this batch size works without any errors. However, it may not work for SharePoint Lists because each item in a List can have one or more attachments and as a result this batch size increases by the number of attachments (2000 * Average no. of attachments per list item). This causes the error above.
To fix this issue, you can increase the values of ‘MaxResourcesPerRequest’ and ‘MaxObjectPaths’ using PowerShell. Note, however, this only applies to SharePoint On-Premises.
To view the existing value for these settings, run the following command in PowerShell:
Get-SPWebApplication | %{$_.ClientCallableSettings}
To increase the values run the following commands:
$webApp = Get-SPWebApplication “<SITEURL>”
$webApp.ClientCallableSettings.MaxObjectPaths = 6000
$webApp.ClientCallableSettings.MaxResourcesPerRequest = 50
$webApp.Update()
A good value for MaxObjectPaths is:
- (‘listBatchSize’(see below) x Average no. of attachments per List Item) - if the error is generated when enumerating documents from a SharePoint List
- a value greater than
libraryBatchSize(see below) - if the error is generated when enumerating documents from a SharePoint Document Library
However, if you’re using SharePoint Online (O365) or if the above solution isn’t feasible for you, there are now two new settings in the Searchlight.config file that can help with this issue:
- listBatchSize
- libraryBatchSize
The default value for both settings is 2000. Reducing the value of these settings will also fix the issue. You will have to reduce the value(s) by trial and error until the error goes away. Usually, a safe value is (‘MaxObjectPaths’ / Max no. attachments in the list items).
Note, however, the smaller the value for listBatchSize and libraryBatchSize, the longer the enumeration will take.
Make sure you restart the Searchlight service after making changes to Searchlight.config.
Version 1.20
Enhancements
Process PDF attachments inside MSG files
In this version, PDF attachments inside MSG files can be processed. The attachments are OCRed and replaced in the MSG files.
Alerts and reports
Aquaforest Searchlight now has the ability to generate scheduled CSV reports to show statistics about the status of a library as a whole as well as show statistics about particular job runs (such as jobs that were run within a particular date range) to find out how many documents were successfully OCRed and how many failed.
Users can set up a report to run daily, weekly, monthly, etc. and automatically send an email with the report attached.
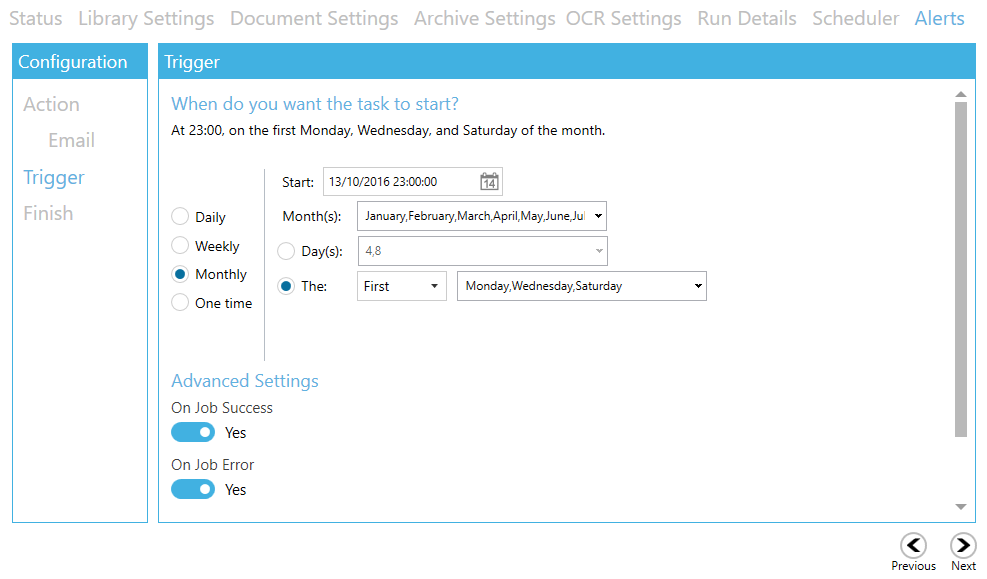
Users can also manually generate CSV reports of previous job runs. To do so, go to the “Run Details” tab, select a run history and click on “Export to CSV”.
64-bit
As of version 1.20, Aquaforest Searchlight is a 64-bit application which means it can now process larger sets of documents as well as large documents concurrently without running out of memory (as long as your system has enough physical memory).
Check service status periodically
In previous versions, if the Searchlight service crashed (e.g., due to being out of memory), the status of a running job was still set to as running on the Dashboard. This was misleading as users would not know the job had stopped unless they manually checked the status of the Searchlight service in the task manager.
In this release, a feature has been added to periodically check the status of the Searchlight service. If the status of a job is set to as running when the service has stopped, it will be put into an error state. The interval for checking the service is controlled by the “checkServiceEvery” option in Searchlight.config file. The default is to check the service every 60 minutes.
Ignore errors when enumerating folders
Folders that can’t be enumerated due to permissions restrictions, long path errors, etc. can now be skipped instead of failing the whole job. This is controlled by the “skipEnumerationErrors” setting in the Searchlight.config file. This setting is only valid for File System sources.
Long path support
When enumerating documents to process, Searchlight can come across documents that exceed the file path length enforced by windows. These files are skipped and not processed.
Starting from Windows 10 and Windows Server 2016, there’s now support for long paths. However, long paths support isn’t enabled by default. You need to enable the following policy to take advantage of this new feature.
Open Global Policy Editor (Start > Run > gpedit.msc) and enable Enable Win32 long paths.
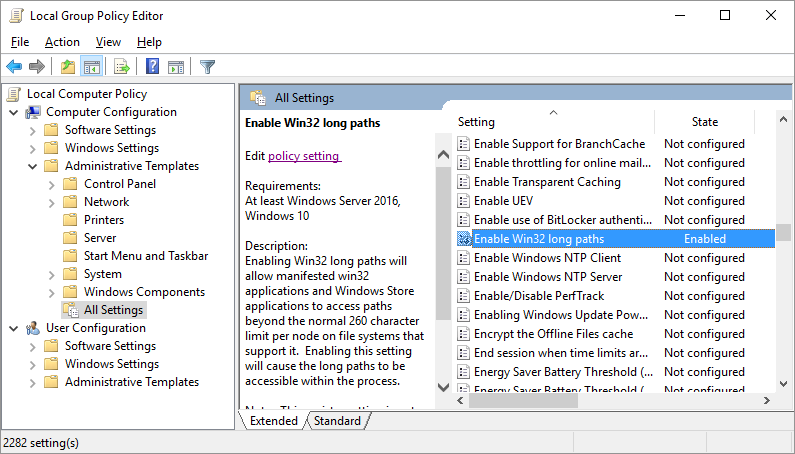
Restart the Searchlight service after making changes to this policy.
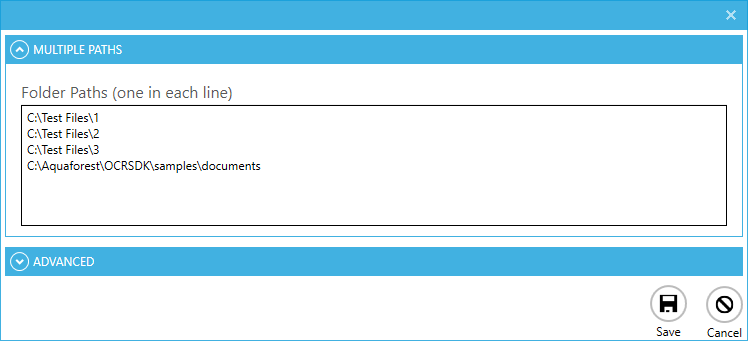
Add multiple file system paths
Multiple file system paths can now be added all at once through the “Multiple Paths” expander as shown below:
Process PDF files with vector objects in native mode
PDF documents that contain only vector images (e.g., CAD drawings) can now be OCRed natively. In previous versions, the PDF needed to be re-imaged before OCRing.
By default, pages that contain only vector objects are rasterized. Pages that don’t have any images but contain vector objects as well as electronic text are skipped from rasterization. However, sometimes there can be a page that contains vector objects (CAD drawings), but its title may be in electronic text. To force rasterizing pages like these, there’s a property called “PdfToImageForceVectorCheck” in the Properties.xml file of the OCR engine being used, which needs to be set to true. Note, however, that this is a global setting and will affect all document libraries using that particular OCR engine.
Font sizing
The sizing of OCRed text added to PDF documents in native mode (i.e., without re-imaging) in the Extended OCR engine (IRIS) has been improved.
FIPS compliancy
Aquaforest Searchlight as well as the OCR engines should now be FIPS compliant.
Temp folder
The “Temp Folder Location” specified in the “Document Settings” tab will also be used to temporarily store OCRed documents in addition to downloaded documents.
Force error when page exceeds pixel limit
A new setting has been added to force a document to error out in Native mode if it has an image in a page that exceeds the pixel limit (IRIS engine only). This is controlled by the “failOnPixelLimit” setting in the Searchlight.config file. The default value is ‘false’ which will cause the page to be skipped.
Extended OCR has the following image limits:
- Max Height = 32,768 pixels
- Max Width = 32,768 pixels
- Max Size = 75,000,000 pixels
Retries
Occasionally, there might be some intermittent network problems or unusual extreme load on the SharePoint server which can cause problems when processing SharePoint document libraries. To cope with this, retry mechanisms have been implemented for different scenarios that will retry performing a particular task in the event of such problems (e.g., timeouts). There are two SharePoint retry settings available:
- downloadAndUploadRetries - used when downloading and uploading documents fail.
- sharePointRequestRetries - used when executing SharePoint queries fail.
The number of retries and the amount of time to wait between retries can be controlled through the respective config settings. The value needs to be entered in the format “x,y”, where x is the number of retries and y is the time (in milliseconds) to wait before the first retry. For subsequent retries, the time to wait will be twice the previous wait time.
This config setting can be found in the “Searchlight.config” file located at:
“[installation path]\config\Searchlight.config”.
Parallel enumeration
When enumerating documents from large SharePoint libraries, Aquaforest Searchlight partitions retrieval so that the documents are retrieved in chunks. In this release, these chunks can be retrieved in parallel which can significantly speed up enumeration. The maximum number of chunks that can be retrieved at once is controlled by the “enumerationMaxParallelism” setting in the “Searchlight.config” file. Note, however, that the maximum value will be limited to the maximum cores your license permits.
Audit page limit
A new feature has been added to limit the number of pages per document to audit. This can be beneficial for documents with lots of pages as it will speed up the audit process. This feature is controlled by the “maxAuditPageCount” in the Searchlight.config file. The default value for this setting is 0, which means that Searchlight will audit all pages of each document.
Check-in comment for failed documents
When a SharePoint document is successfully OCRed, a comment indicating the file was processed by Aquaforest Searchlight is added during check-in. This check-in comment can be configured in the “Library Settings” tab. However, when a document fails to OCR, no comment is added.
To force Searchlight to add a comment to the original non-OCRed document in SharePoint, specify a comment in the “sharePointFailCheckinComment” setting in the Searchlight.config file.
Bug fixes
Scheduler
The scheduler option “Continuous every x days” did not work properly. This has now been fixed.
UI crash
Fixed issue where the UI crashed if values from drop-down menus were selected when there was no document library in Aquaforest Searchlight.
Version 1.10
Enhancements
Updated Extended OCR engine
Aquaforest Searchlight 1.10 now has the latest version of the iDRS engine (iDRS 15) in the Extended OCR engine. It provides the following new features:
- Better character recognition
- Additional output formats such as PDF/A-1a
- New Asian OCR engine
- JPEG2000 Compression
Reimage PDF
Both the Aquaforest and the Extended engines now have the option to re-image source PDF (also known as ‘Convert to TIFF’), which rasterizes each page of the PDF document and adds them to a new PDF with the OCRed text layer.
Convert PDF to PDF/A
Previous versions of Aquaforest Searchlight only allowed converting TIFF files to PDF/A. With the newly added “Re-image PDF” option, PDF documents can also be converted to PDF/A.
Support for additional image types (BMP, JPEG and PNG)
This release of Aquaforest Searchlight can process BMP, JPEG and PNG files in addition to TIFF and PDF files.
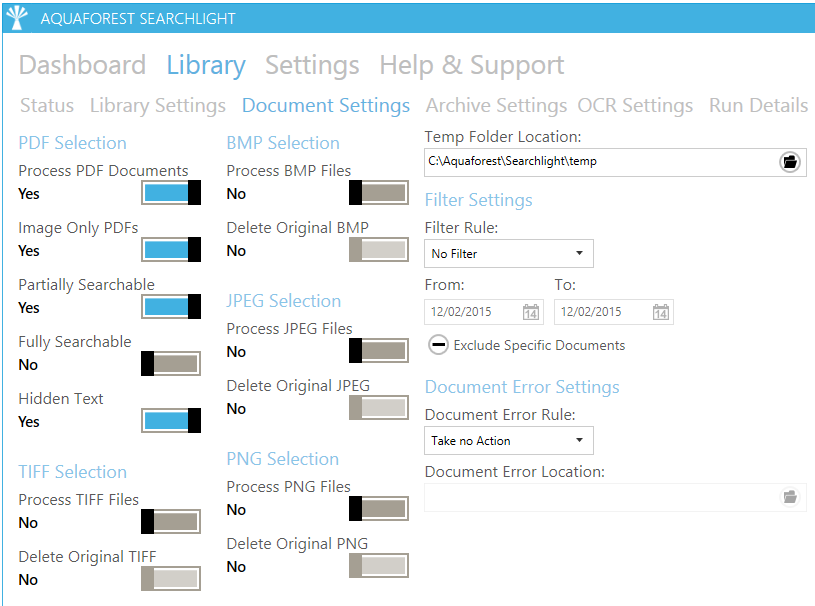
Exclude specific documents
Specific documents can now be excluded from processing (both Audit and OCR). Documents to be excluded can be set through Filter Settings on the Document Settings page.
Temp location
The temporary folder used to keep files before auditing and OCR can now be set through the UI rather than the Searchlight.config file.
Active Directory Federation Service (AD FS) login
Aquaforest Searchlight now supports login to SharePoint Online (Office 365) configured to use AD FS.
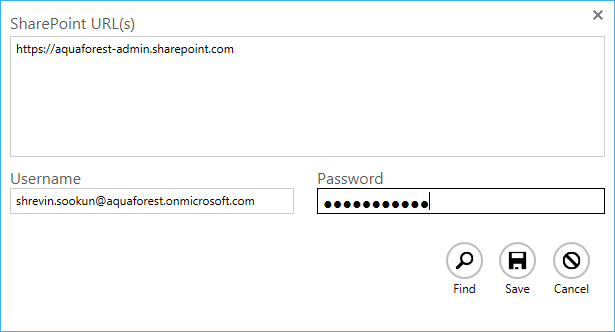
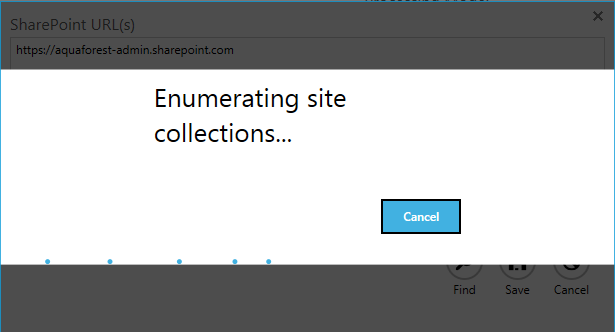
Enumerate site collections
Aquaforest Searchlight can now enumerate site collections if the root admin URL is provided. This will facilitate adding multiple site collections at once. This feature is only available for Office 365.
 |  |
|---|
Retrieve documents from SharePoint lists that exceed the List View Threshold
Aquaforest Searchlight can now get documents from SharePoint document libraries/lists that have more items than their List View Threshold.
Audit and OCR documents one by one
In previous versions of Aquaforest Searchlight, for SharePoint document libraries, all candidate documents were downloaded first before performing Audit and OCR. However, this required a considerable amount of free space in the local computer if the document library being processed was really big or if several document libraries were being processed at the same time.
In this release, documents are audited as soon as they are downloaded. If the processing mode is “Audit and OCR” and there is enough space in the local computer, the same downloaded documents can be used for OCR after all documents have been audited. However, if space is an issue, the documents can be deleted as soon as they have been audited and they will be downloaded again during the OCR process. To delete the documents after audit, the setting “deleteDocumentsAfterAudit” needs to be set to true in the Searchlight.config file.
Default OCR settings
In previous versions of Aquaforest Searchlight, OCR settings were hard coded in the application. In this release, the OCR settings are loaded from the properties.xml file of the OCR engine being used.
- Aquaforest engine: “[installation path]\tj\bin\ocr\Properties.xml”
- IRIS (Extended) engine: “[installation path]\extendedocr\Properties.xml”
This can be useful if you have a set of OCR settings that work best for the type of documents you have and want to use the same OCR settings for all newly created document libraries.
Note: Aquaforest Searchlight doesn’t modify the Properties.xml file. To set default values, you need to manually update the relevant Properties.xml file.
Ignore previously OCRed documents
Searchlight may re-OCR documents that have already been processed previously if its modified date in SharePoint has changed since the last time it was processed and process “Fully Searchable” and/or “Partially Searchable” options are set in the Document Settings. The modified date can change if a document is replaced by a new one or its metadata/properties are modified in SharePoint.
To avoid re-processing these documents again irrespective of whether the modified has changed, set the “ignorePreviouslyOcredDocuments” setting to true in Searchlight.config. The default value is false.
Skip checked-out documents
It is now possible to skip checked-out documents from being processed (during OCR stage only). This is controlled by the “skipCheckedOutDocument” setting in Searchlight.config. The default value is true.
Retain Approval Status
When Aquaforest Searchlight processes documents in a SharePoint library which requires Content Approval, it will set them to ‘Pending’ after processing. To retain the original Approval Status after the documents have been processed, set the “retainApprovalStatus” setting to ‘true’ in Searchlight.config.
Note: If this setting is set to true, the “Retain Modified Date” in Aquaforest Searchlight won’t work.
Audit chart
A new feature has been added that enables users to view the audit results in a more user-friendly graphical report as shown below. This report can be generated by going to Library 🡪 Status and click on the Report button.

Performance
The performance of several database heavy operations have been improved such as retrieving Run History/Details and deleting large document libraries.
Database locks
When processing a document library using multiple cores, there used to be lots of “Database is locked” messages that were generated, which sometimes crashed the Aquaforest Searchlight service. This has been fixed in this release. However, it is still possible to get database locks when processing several document libraries at once using multicore, but the frequency should be significantly reduced.
UI changes
The following pages have been restructured to make them more user friendly:
- Library 🡪 OCR Settings
- Library 🡪 Run Details
- Library 🡪 Document Archive Settings
- Settings 🡪 License
- Settings 🡪 Theme
New themes
There are now 23 different Accent colors to choose from both Light and Dark themes. The default is Light Blue.
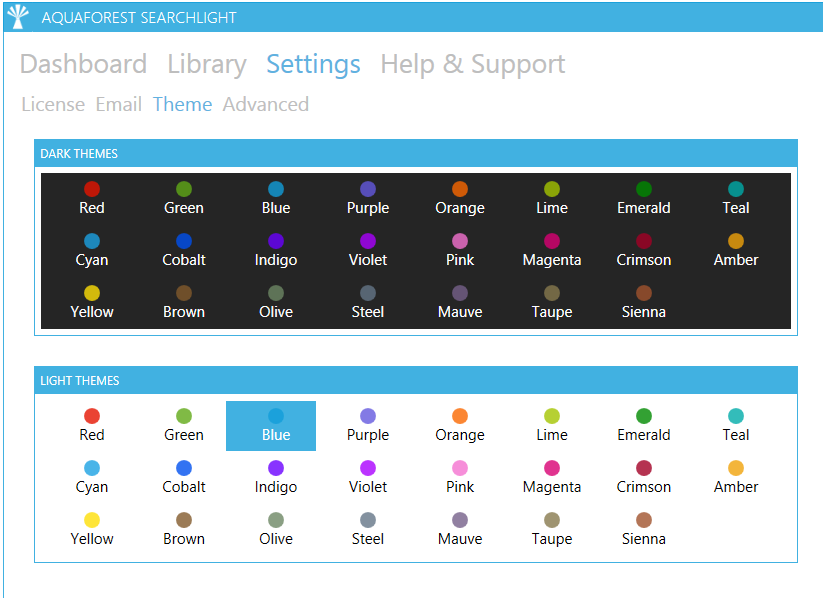
Version 1.05
Enhancements
Add Multiple SharePoint URLs
Multiple SharePoint URLs can now be added at once using the new enhanced Add New Location wizard. Each URL must be in a new line as shown below.
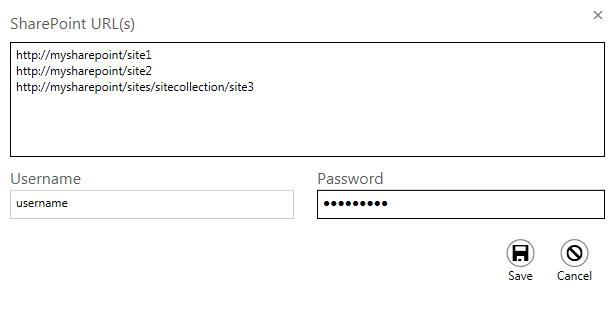
Download progress
The dashboard now displays the progress when downloading documents in the following format:
“Downloading x of y”.
Download retries
Occasionally, there might be some intermittent network problems which can cause problems when downloading files from SharePoint for processing. To cope with this, a retry mechanism has been implemented that will retry downloading in the event of such network problems. The number of retries and the amount of time to wait between retries can be controlled through the following config setting:
<add key=“downloadRetries” value=“5,1000” />
The value needs to be entered in the format “x,y”, where x is the number of retries and y is the amount of time in milliseconds to wait for each retry.
This config setting can be found in the “Searchlight.config” file located at:
“[installation path]\config\Searchlight.config”.
Database update retries
Sometimes, if a document library is set to process using multiple cores, Searchlight may encounter problems when it tries to update the database due to it being ‘locked’ because of concurrent updates. To overcome this problem, a retry mechanism has been implemented that will retry updating the database if it fails the first time. The number of retries and the amount of time to wait between retries can be controlled through the following config setting:
<add key=“databaseRetries” value=“5,1000” />
The value needs to be entered in the format “x,y”, where x is the number of retries and y is the amount of time in milliseconds to wait for each retry.
This config setting can be found in the “Searchlight.config” file located at:
“[installation path]\config\Searchlight.config”.
Form-based authentication
Searchlight can now process SharePoint libraries that require form-based authentication.
Remove hidden text
Existing hidden text (text that was added as a result of a previous OCR) can now be removed from the PDF file so that the resulting searchable PDF file doesn’t have two layers of the same text. This can be achieved by setting the “Remove Hidden Text” option to True.
Remove visible text
Visible text (text as a result of conversion from an electronic document such as Word to PDF) can now be excluded from the OCR process. This only affects engine 2 of Aquaforest OCR and the Extended OCR (IRIS engine).
To enable this feature:
- Aquaforest OCR - set “PdfToImageIncludeText” to False in properties.xml
- Extended OCR – set “Remove Visible Text” to True from General OCR Settings in the GUI.
Retain creation/modified date/user
In this release of Aquaforest Searchlight, there is the extended functionality of retaining created date, modified user, created user and modified user of documents.
| Creation Date | Created User | Modified Date | Modified User | |
|---|---|---|---|---|
| SharePoint | ✔ | ✔ | ✔ | ✔ |
| PDF metadata | ✔ | ✔ | ✔ | N/A |
| Windows File System | ✔ | ✔ | ✔ | N/A |
“Create User” maps best to “Owner” in Windows File System metadata. For this to be manipulated Searchlight would need to be running with sufficient administrative privileges.
Note: Previous versions of Aquaforest Searchlight had two options “Retain SharePoint TIFF Creation Date” and “Retain Creation Date” which have now been merged to one option namely “Retain Creation Date”. If any of the two options were set to ‘True’ in the previous version, it will be carried over to the new field.
Multicore support
In this version, the support for multicore processing has been increased from 8 cores to 64 cores.
Bug fixes
SharePoint template types
In previous versions of Searchlight, only document libraries and lists with Server Template IDs 101 and 100 respectively were processed. As a result, document libraries and lists created using custom templates were skipped. This has now been fixed.