Contracts, filings, and agreements hold the data your business runs on. Nutrient Data Extraction API extracts it as typed, auditable JSON — with source coordinates and confidence scores, so nothing moves downstream unreviewed.

Trusted by enterprises, governments, and teams building document workflows at scale
USE CASES
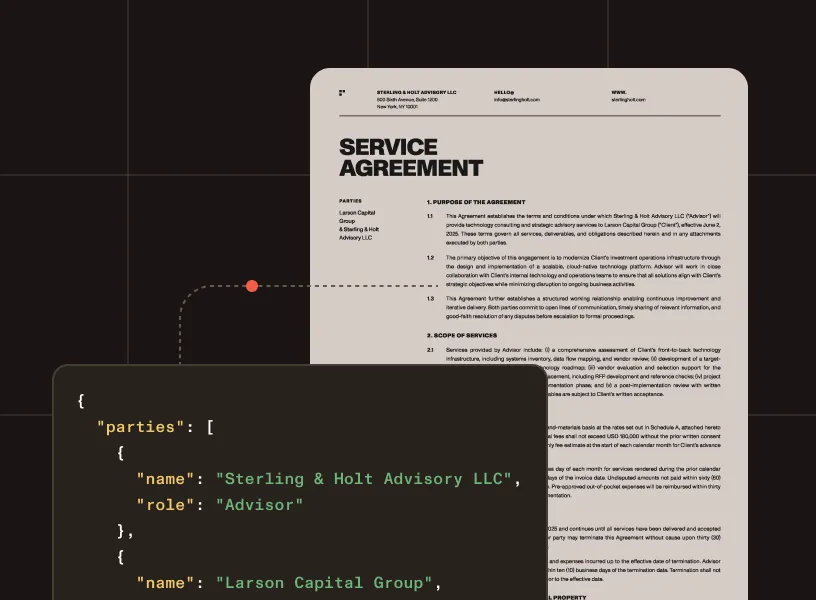
Extract parties, dates, payment terms, renewal terms, obligations, and document metadata from contracts and agreements.
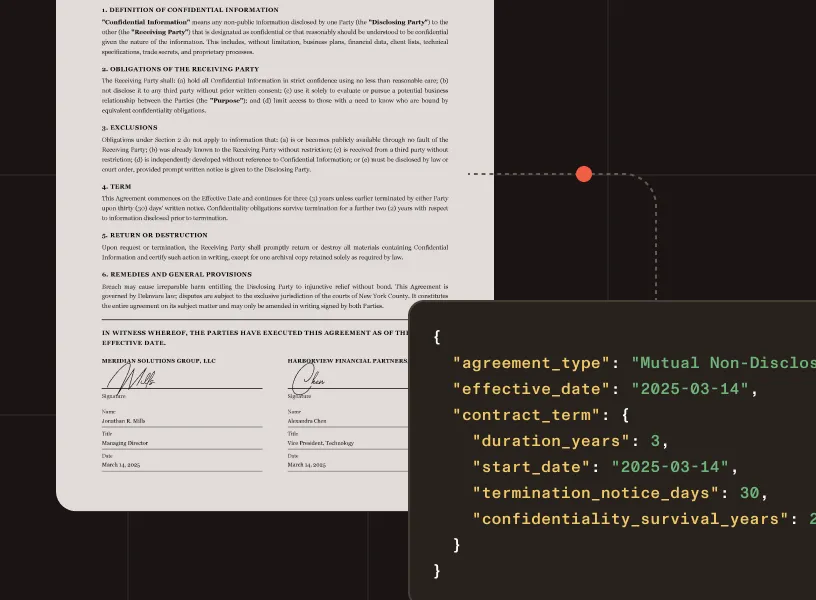
Identify and structure clause text from contracts, amendments, NDAs, schedules, and supporting documents.
Turn legal documents into structured Markdown or typed JSON for search, knowledge bases, document Q&A, and AI workflows.

Use source context, confidence, and page details to support reviewable, traceable legal document workflows.
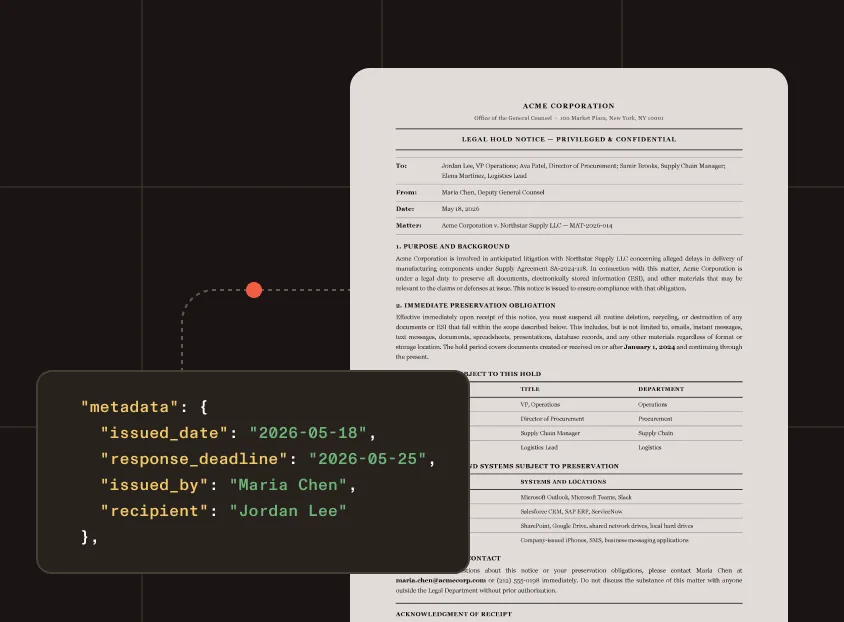
Extract metadata, key-value fields, and document structure from legal hold documents and matter files for review and triage.
GOVERNED EXTRACTION
LLMs can reason over documents — but legal workflows need deterministic, auditable output grounded in the source file, not generated answers that vary between runs.
Typed output remains tied to the source document — not generated answers that change between runs.
Route uncertain values for human review before they enter downstream legal or compliance systems.
Every extracted value is anchored to its source location for traceability and audit.
Clauses, tables, and key-value regions preserved — not flattened into unstructured text.
Support review and validation steps before data enters contract management, compliance, or matter systems.
Source context and page detail support traceable, audit-ready legal document workflows.
WALKTHROUGH

WHAT YOU CAN EXTRACT
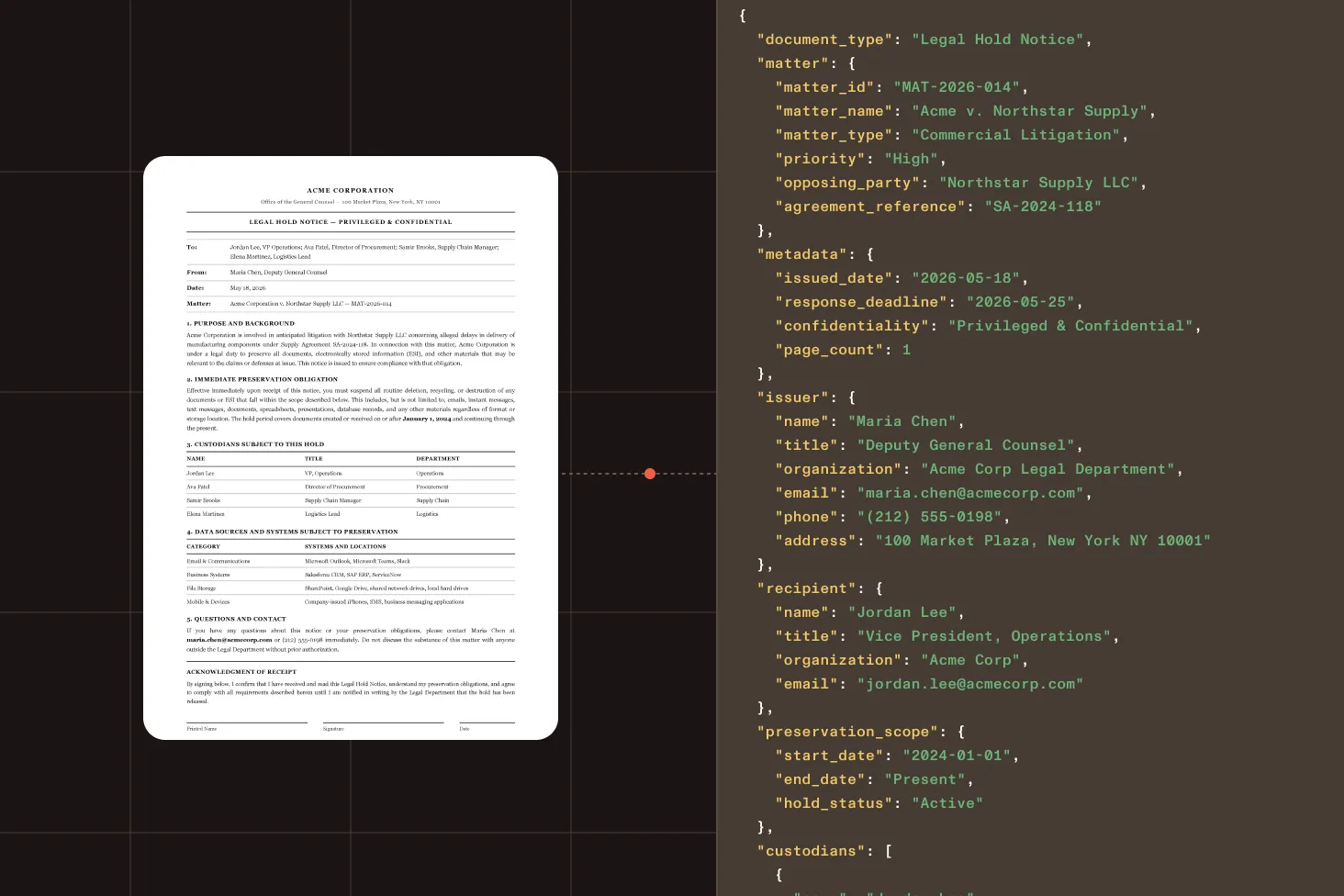
Legal names, roles, addresses, and identifiers for all contract parties and signatories.
Effective dates, termination dates, renewal windows, and notice periods extracted with source coordinates.
Extracted clause content with source location for validation before it enters contract management or compliance systems.
Amounts, payment schedules, late fees, and currency fields from contracts and amendments.
Signatory names, roles, dates, and signature presence indicators from executed documents.
Structured data from exhibits, schedules, and supporting documents, preserved with row and column context.
HOW IT WORKS
Parse
Turn legal PDFs, scans, images, and Office files into document structure.
Extract
Identify clauses, tables, key-value regions, signatures, dates, and parties.
Map
Define the fields your workflow needs using the schema generator in Studio, or write a JSON Schema directly. Get back validated, typed output.
Structure
Return typed JSON for systems and validation, or Markdown for search and AI workflows.
Process
Send structured data into review queues, contract management, compliance workflows, or business systems.
OUTPUT FORMATS
Confidence scores, coordinates, and page context included.
Choose output: "json" or Markdown per request.
Spatial JSON
For extraction · validation · review
{ "status": "processed", "pages": [{ "elements": [ { "type": "key_value_pair", "label": "Effective date", "value": "2024-01-15", "confidence": 0.99, "page": 1, "bounds": [82, 128, 284, 152] }, { "type": "key_value_pair", "label": "Contract value", "value": "$240,000", "confidence": 0.98, "page": 2, "bounds": [82, 320, 284, 344] } ] }]}Markdown
For RAG · search · knowledge bases
# Master Services Agreement
**Party A** Acme Corp**Party B** Vendor Inc**Effective** January 15, 2024
## Payment Terms
Payment due within 30 days of invoice.Late fees: 1.5% per month.
**Governing law** State of DelawareRegional processing options
Choose supported processing regions for enterprise deployments.
SOC 2 Type 2 audited
Audited annually. Reports available under NDA for enterprise customers.
Trust and compliance
TLS encryption by default
All API communication is encrypted. Unencrypted requests are rejected.
Privilege and confidentiality controls
No retention, encrypted transport, and access controls designed for governed legal document workflows.
Yes. The API identifies and extracts clause text, key-value regions, tables, and structured fields from contracts, amendments, NDAs, and other legal documents — with source coordinates and confidence scores so teams can validate values before they enter downstream systems.
Data Extraction API processes PDFs, scanned documents, images, Word, Excel, and PowerPoint files. It handles scanned PDFs, complex layouts, and mixed digital/image-based documents without requiring a separate OCR pipeline.
Nutrient Data Extraction API is an extraction layer, not a contract lifecycle management platform. It extracts structured data from legal documents so that data can be reviewed, validated, and routed into contract management, compliance, matter management, or business systems your team already uses.
Every extracted element includes confidence scores, page references, and coordinates so you can flag low-confidence fields for human review, trace values back to the source document, and validate clause text and metadata before anything moves into downstream legal or compliance systems.
Use the schema generator in Studio — upload example contracts, filings, or agreements and describe the document type. It then generates a JSON Schema you can use directly with `/extract`. You can also write the schema manually for fields like parties, dates, payment terms, and clause text. Refer to the documentation for supported field types and limits.
Use agentic mode for legal documents that require the deepest visual understanding — degraded or faxed filings, complex scanned documents, handwritten annotations, and documents with embedded images or diagrams where understand mode produces insufficient results. Agentic mode adds a vision language model (VLM) on top of the understand pipeline. It costs 18 credits per page.




