Healthcare teams spend hours manually keying data from forms, records, and scanned documents. Nutrient Data Extraction API turns those documents into validated, traceable structured data, so your team reviews exceptions, not every field. The architecture has no document retention and uses encrypted transport and access controls designed to support HIPAA-sensitive workflows.

Trusted by enterprises, governments, and teams building document workflows at scale
USE CASES

Extract patient demographics, insurance details, consent fields, checkboxes, signatures, and supporting information from intake documents.

Structure provider, payer, procedure, diagnosis, date, authorization, and supporting information for review and routing.

Automate extraction of payer details, dates, amounts, codes, patient responsibility, payment details, and structured tables from EOBs and claims documents.
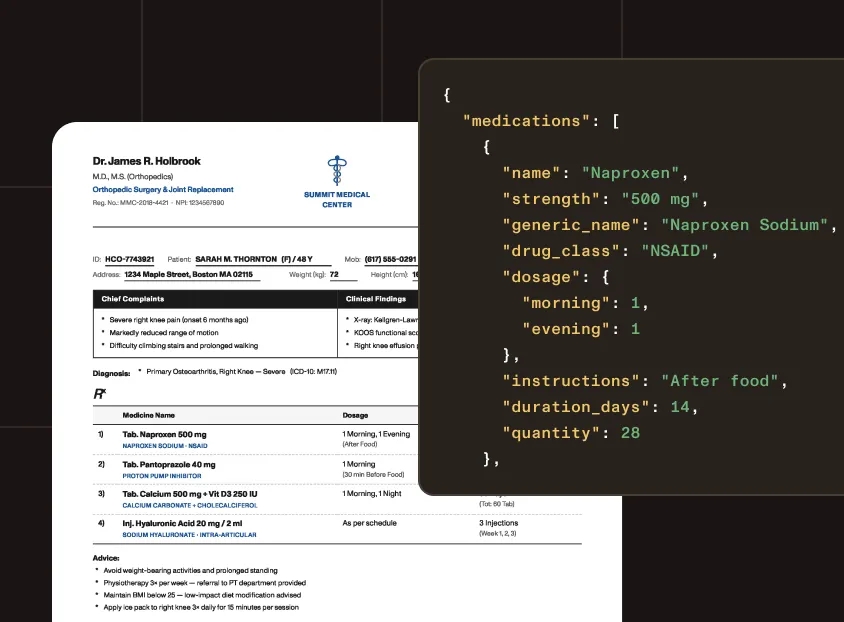
Extract test names, values, reference ranges, dates, prescription details, provider information, and structured fields from lab and prescription documents.
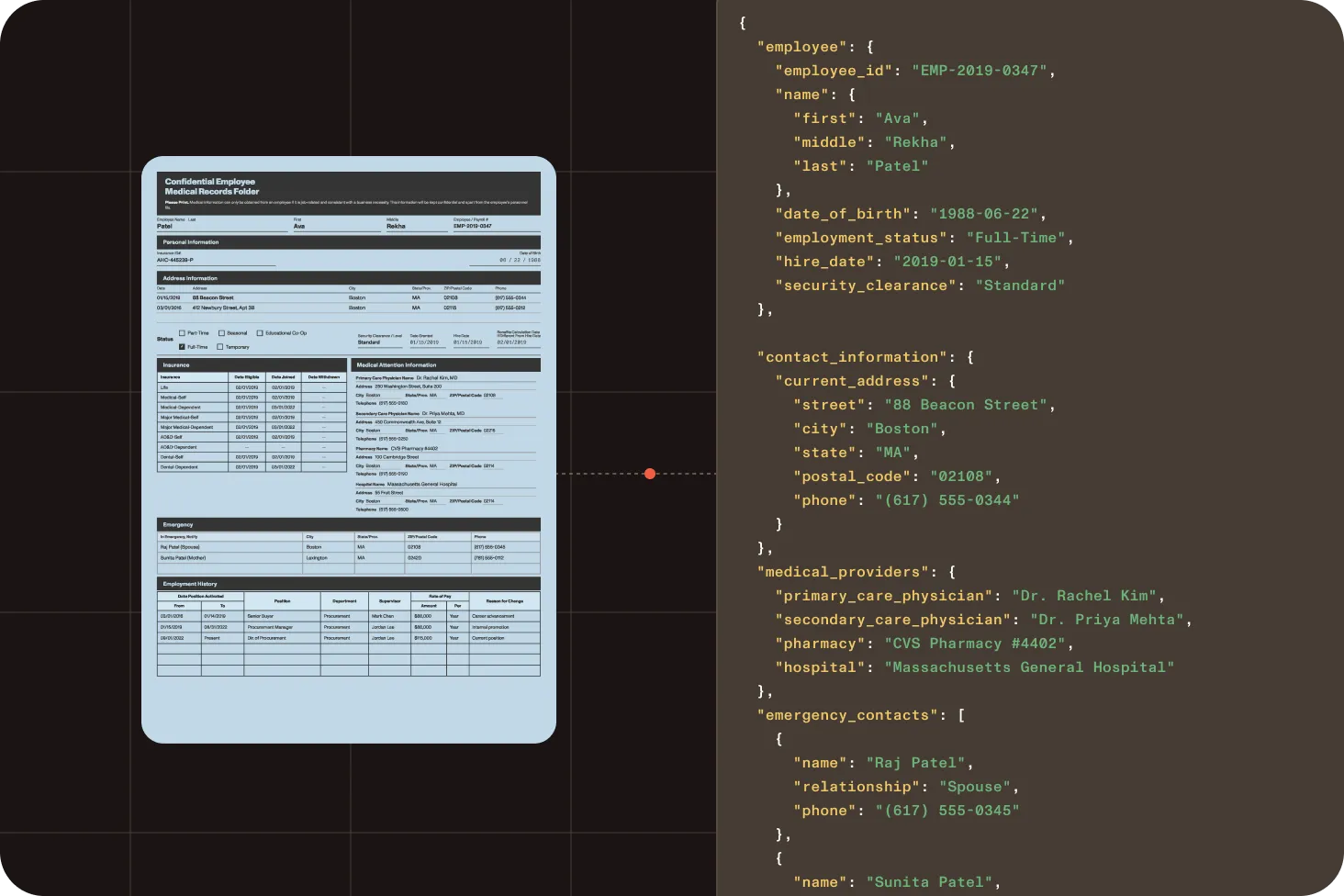
Prepare mixed scanned and digital medical records for review, search, AI, and downstream workflow use.
WALKTHROUGH

GOVERNED EXTRACTION
LLMs can reason over documents — but medical workflows need deterministic, auditable output grounded in the source file, not generated answers that vary between runs.
Typed output remains tied to the source document — not generated answers that change between runs.
Flag uncertain values before they move downstream into patient records or administrative systems.
Every extracted value is anchored to its source location for traceability and human review.
Tables, forms, checkboxes, and key-value regions preserved — not flattened into plain text.
Support validation steps before structured data enters patient records, claims systems, or administrative workflows.
Source context and page detail support audit trails in regulated healthcare environments.
WHAT YOU CAN EXTRACT
Names, DOBs, NPI numbers, addresses, and identifiers from intake and referral documents.
ICD-10, CPT, and related codes extracted with confidence scores for validation before downstream use.
Payer names, policy numbers, group IDs, and coverage details from insurance and claims documents.
Test names, result values, units, and reference ranges preserved from lab reports.
Structured key-value regions, handwritten fields, and checkbox states captured with ICR — with confidence scores for review.
Tables from EOBs, prior authorization forms, and claims documents, preserved with row and column context.
HOW IT WORKS
Parse
Turn medical PDFs, scans, images, and Office files into document structure.
Extract
Identify text, tables, forms, handwriting, checkboxes, codes, dates, and signatures.
Map
Define the fields your workflow needs using the schema generator in Studio, or write a JSON Schema directly. Get back validated, typed output.
Structure
Return typed JSON for systems and validation, or Markdown for search and AI workflows.
Process
Send structured data into review queues, administrative workflows, or downstream applications.
OUTPUT FORMATS
Confidence scores, coordinates, and page context included.
Choose output: "json" or Markdown per request.
Spatial JSON
For extraction · validation · review
{ "status": "processed", "pages": [{ "elements": [ { "type": "key_value_pair", "label": "Patient name", "value": "Sarah Chen", "confidence": 0.99, "page": 1, "bounds": [82, 128, 284, 152] }, { "type": "key_value_pair", "label": "Diagnosis code", "value": "J45.40", "confidence": 0.97, "page": 1, "bounds": [82, 164, 220, 188] } ] }]}Markdown
For RAG · search · knowledge bases
# Patient Intake Form
**Patient** Sarah Chen**DOB** 1985-03-12**Insurance ID** UHC-8821047
## Diagnosis
| Code | Description || --- | --- || J45.40 | Moderate persistent asthma |
**Provider** Dr. Marcus Webb**Date** 2024-11-08Regional processing options
Choose supported processing regions for enterprise deployments.
SOC 2 Type 2 audited
Backed by Nutrient’s SOC 2 Type 2 security practices, built for use in business-critical and compliance-sensitive workflows.
Trust and compliance
TLS encryption by default
All API communication is TLS-encrypted. Documents in transit are protected end to end.
HIPAA-compatible architecture
No document retention, encrypted transport, and access controls designed to support HIPAA-sensitive workflows.
Yes. For hand-completed fields, checkboxes, and handwritten values, the API applies intelligent character recognition (ICR) to capture what standard OCR misses. Every extracted value includes a confidence score so uncertain fields can be flagged for human review before moving downstream.
Data Extraction API processes PDFs, images (including scans and photos), Word, Excel, and PowerPoint files. It handles scanned PDFs, fillable forms, and mixed digital/image-based documents without requiring a separate OCR pipeline.
Every extracted element includes confidence scores, page references, and coordinates so you can compare outputs, flag low-confidence fields for human review, and trace values back to the source document before they move into patient records, claims systems, or administrative workflows.
Nutrient Data Extraction API is an extraction layer — not an EHR, claims platform, or workflow management system. It extracts structured data from medical documents so that data can be reviewed, validated, and routed into the systems your team already uses.
Use the schema generator in Studio — upload example forms, records, or claims documents and describe the document type. It then generates a JSON Schema you can use directly with `/extract`. You can also write the schema manually for fields like patient details, diagnosis codes, dates, and payer information. Refer to the documentation for supported field types and limits.
Use agentic mode for medical documents that require the deepest visual understanding — degraded scans, faxed records, low-quality images, handwriting, and documents with embedded images or diagrams where understand mode produces insufficient results. Agentic mode adds a vision language model (VLM) on top of the understand pipeline for complex visual content. It costs 18 credits per page.




