










“Nutrient allows us to move a few thousand feet above the day-to-day.
The system automates daily so we can focus on improving service
management.”
GLAXO SMITH KLINE
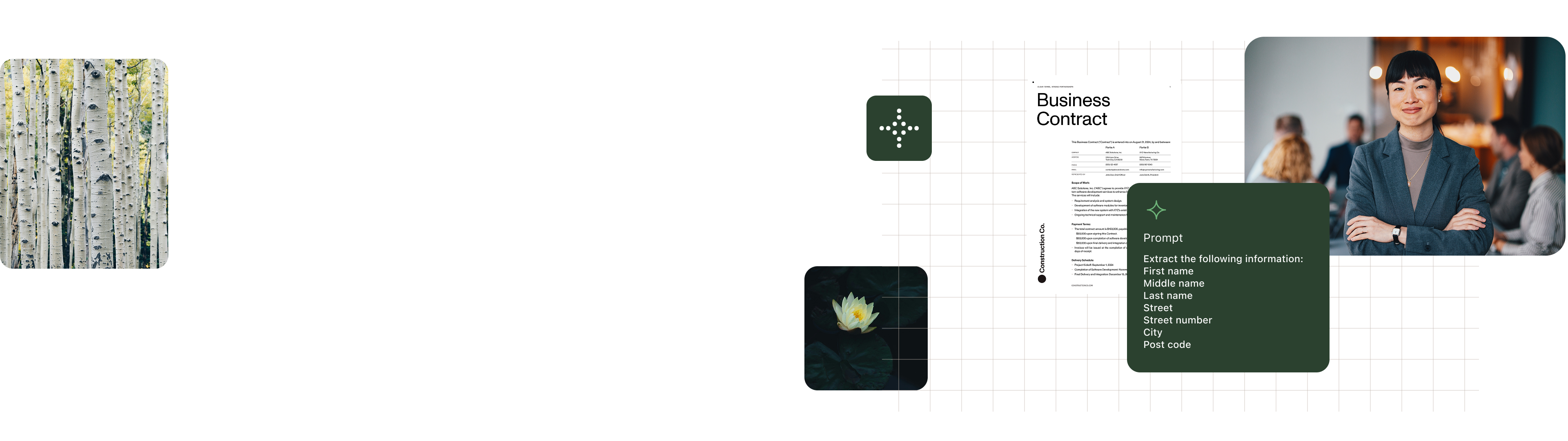
Nutrient intelligent document processing transforms PDFs, scans, and emails into clean, structured data — ready to populate forms, trigger tasks, or fuel integrations.
Extract applicant data, prepopulate forms, and drive decision tasks automatically.
Capture vendors, totals, and due dates and route for validation or payment.
Classify document types, extract key clauses, and trigger approval workflows.
Process scanned files, validate metadata, and route based on content and context.

KEY FEATURES
AI-driven data capture with built-in rules, validation, and output formats — at any scale.
Process PDFs, Office documents, images, emails, scans — all in one streamlined pipeline.
Define extraction instructions using plain language and let the AI identify the fields — no complex rule‑writing required.
Handle thousands or millions of documents with performance‑tuned classification and data extraction.
Export data in structured formats (JSON, CSV, XML) or feed directly into your systems — no manual cleanup required.
Combine LLM‑powered extraction with built‑in validators and business rules to ensure high accuracy and compliance.
Deploy in the cloud, on‑premises, or hybrid — align document processing with your governance, retention, and privacy policies.
PROVEN AT SCALE
Reduced workflow costs by more than 30 percent, cut cycle times in half, and achieved ROI in less than three months. Now 100+ employees across LA and London rely on Nutrient Workflow for 15+ processes in content operations and reporting.
Standardized global IT request management with Nutrient Workflow — processing 16,000+ requests per month across 60 countries. Cut costs by up to 90 percent per transaction and simplified user requests with one universal interface.
Automated financial aid, transportation, and audit workflows — cutting approval times from 7 days to 1–2 days. Achieved 100 percent documentation consistency for audit readiness and strengthened federal grant compliance.
Meet the AI Form Builder Agent — a new capability in Nutrient Workflow that instantly generates complex, ready-to-use forms using natural language or uploaded files.
INTEGRATIONS AND DEPLOYMENT
Built to connect, built to scale — without brittle integrations or vendor lock-in.
| Native integrations | Flexible deployment models |
|---|---|
| SharePoint and Exchange | Cloud |
| SAP, SQL Server, Deltek | Private cloud |
| Salesforce, HubSpot | Self-managed/on-premises |
| Email, SFTP, monitored inboxes | Hybrid deployments |
| Power Automate, Zapier, AWS Lambda | |
Nutrient turns unstructured documents into structured, auditable data — with full control over accuracy, compliance, and scale.
Reduce manual data entry and let extracted information kick off tasks, approvals, or integrations automatically.
Avoid errors from manual keying and gain full traceability on how each document was classified and processed.
Whether it’s ten forms or ten thousand files a day — scale your document workflows with the same infrastructure.
Meet compliance and audit requirements with clear metadata, version‑controlled templates, and secure processing.
Cut cycle time, reduce risk, and simplify document-heavy operations with an execution-first workflow model.
FREE TRIAL
IDP refers to the use of AI and automation to extract data from documents like PDFs, emails, images, or scans — and convert it into structured, usable formats (like JSON or CSV). Nutrient embeds this directly into your workflows.
Nutrient supports a wide range — including PDFs, scanned images, DOCX files, forms, emails, invoices, and attachments. You can train the system to extract the right data from each format.
No. You can define extraction instructions using natural language or label documents with examples. Nutrient combines LLMs with structured validators — no complex scripting required.
Nutrient combines AI extraction with built-in validation logic and optional human review — giving you high accuracy for even messy documents or inconsistent formats.
Yes. Nutrient outputs structured data in JSON, CSV, XML, or direct API integrations — making it easy to feed downstream systems like ERPs, CRMs, or databases.
You choose. Nutrient supports cloud, on-premises, hybrid, or region-specific deployments — giving you full control over data residency, retention, and compliance.

