HTML to PDF in Python: Convert HTML using wkhtmltopdf and pdfkit
Table of contents

Install pdfkit and the wkhtmltopdf binary. Then convert HTML to PDF in three lines:
import pdfkit
pdfkit.from_url('https://example.com', 'out.pdf') # from a URLpdfkit.from_file('index.html', 'out.pdf') # from a filepdfkit.from_string('<h1>Hello</h1>', 'out.pdf') # from a stringIf you’re looking for a way to convert HTML to PDF using Python, this post will show you how to do it efficiently using wkhtmltopdf(opens in a new tab).
wkhtmltopdf was archived on 2 January 2023(opens in a new tab) and is now read-only. The library still works, but receives no security patches, browser-engine updates, or bug fixes. For new projects, consider maintained alternatives — WeasyPrint(opens in a new tab) (BSD, pure Python), Puppeteer(opens in a new tab) or Playwright(opens in a new tab) (Node.js, Chromium-based), or Nutrient’s HTML-to-PDF API for a managed cloud option. This guide remains for teams maintaining existing wkhtmltopdf integrations.
If you’re looking for a way to convert HTML to PDF using Python, this post will show you how to do it using wkhtmltopdf(opens in a new tab) and python-pdfkit(opens in a new tab) — a Python wrapper around the wkhtmltopdf binary. Common use cases include generating invoices, shipping labels, resumes, and reports.
How to pick a Python HTML-to-PDF library
| Library | Best for | Active? | License |
|---|---|---|---|
| wkhtmltopdf + python-pdfkit | Simple static HTML, invoices, reports | ⚠️ Deprecated (last release 2022) | LGPL / MIT |
| WeasyPrint | Print-quality typography, paged media CSS | ✅ Active | BSD-3 |
| Playwright/Pyppeteer | Modern JavaScript-heavy pages, dynamic content | ✅ Active | Apache-2.0 |
| Nutrient HTML-to-PDF API | Production apps, no binary install, scale | ✅ Active | Commercial |
This tutorial covers the wkhtmltopdf + pdfkit path. If your HTML uses modern CSS or JavaScript-rendered content, consider WeasyPrint or Playwright instead.
Note: Both wkhtmltopdf and python-pdfkit are now deprecated. They still work for simple cases, but new projects should consider an actively maintained alternative — see the table above.
Installing wkhtmltopdf
Before you can use wkhtmltopdf, you need to install it on your operating system.
On macOS
Install with Homebrew (the cask still installs the final 0.12.6 build):
brew install --cask wkhtmltopdfOn Debian/Ubuntu
The version in the default APT repositories is built without the wkhtmltopdf Qt patches, so outlines, headers, footers, and TOC support are disabled. For full functionality, download the latest .deb from the wkhtmltopdf releases page(opens in a new tab):
sudo dpkg -i wkhtmltox_*.debsudo apt-get install -fOn Windows
Download the latest installer from the wkhtmltopdf website(opens in a new tab). Then add the wkhtmltopdf binary to your PATH environment variable.
Installing python-pdfkit
Install python-pdfkit using pip:
pip install pdfkit# orpip3 install pdfkit # for Python 3python-pdfkit provides several APIs(opens in a new tab) to create a PDF document:
- From a URL using
from_url - From a string using
from_string - From a file using
from_file
Creating a PDF from a URL
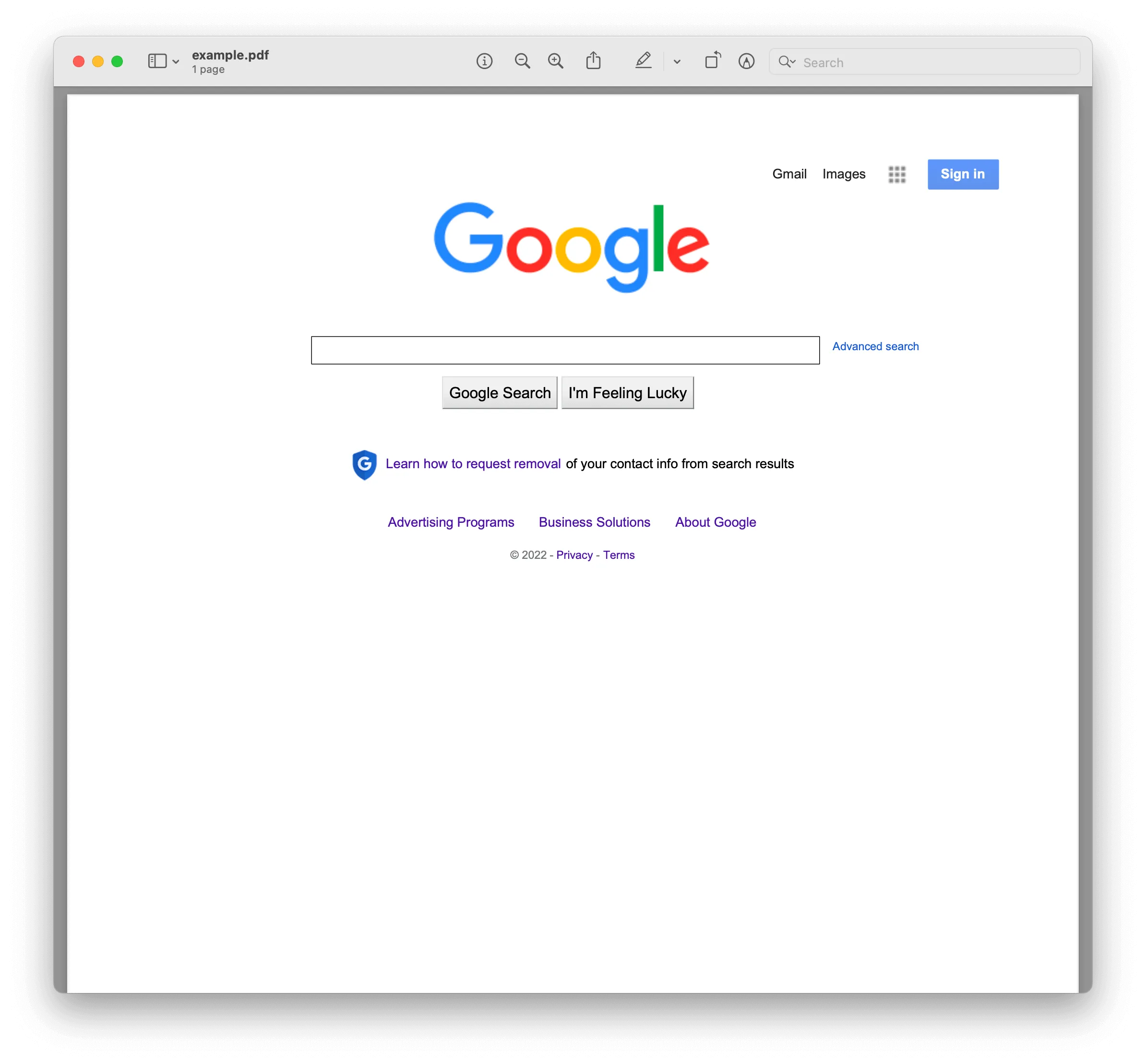
The from_url method takes two arguments: the URL and the output path. The following code snippet shows how to convert the Google home page to PDF using pdfkit:
import pdfkit
pdfkit.from_url('https://google.com', 'example.pdf')Running the code
This section outlines two options for running the code.
Option 1: Direct execution
- Save the code snippet in a file named
url.py. - Run the script:
python url.pyIf you’re using Python 3 and the default Python command points to Python 2, use:
python3 url.pyOption 2: Using a virtual environment
Create a virtual environment:
Terminal window python3 -m venv venvActivate the virtual environment:
Terminal window source venv/bin/activateInstall pdfkit:
Terminal window pip install pdfkitSave the code snippet in a file named
url.pyand run the script:Terminal window python url.py
The output PDF will be saved in the current directory as example.pdf.
Creating a PDF from a string
The from_string method takes two arguments: the HTML string and the output path. The following code snippet shows how to do this:
import pdfkit
pdfkit.from_string('<h1>Hello World!</h1>', 'out.pdf') 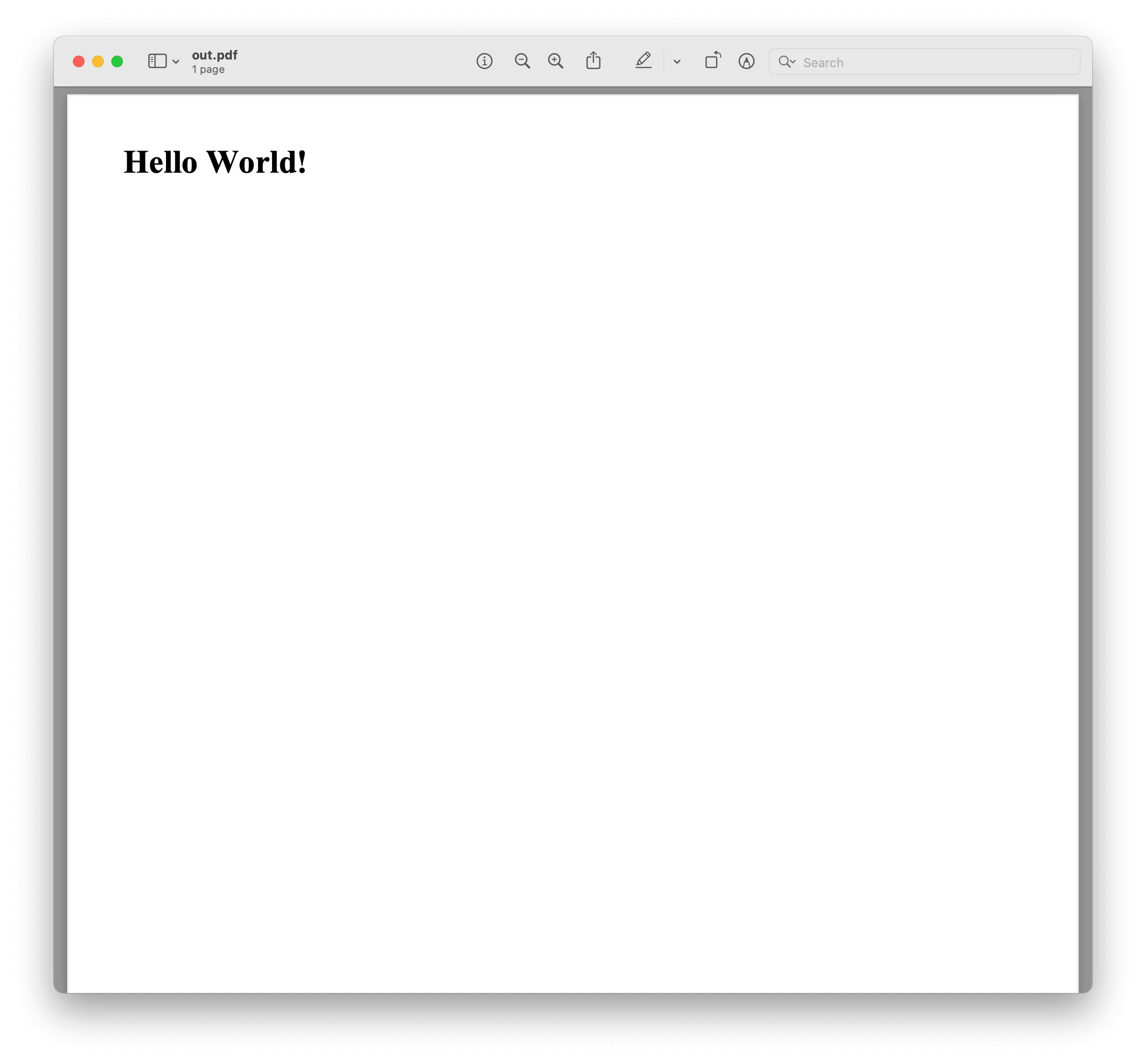
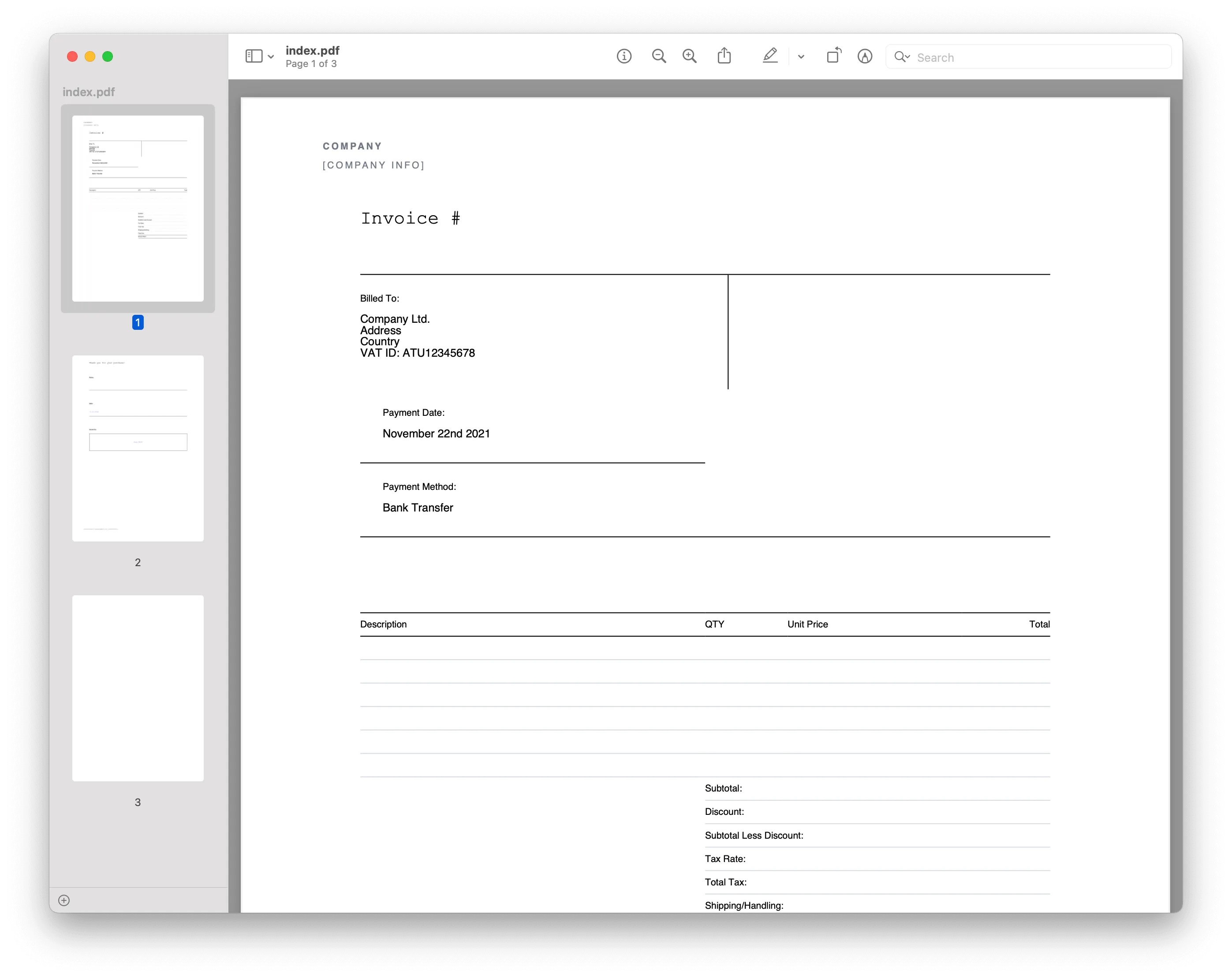
Creating a PDF from a file
The from_file method takes two arguments: the path to the HTML file and the output path. The following code snippet shows how to do this:
import pdfkit
pdfkit.from_file('index.html', 'index.pdf')You’ll use an invoice template for the HTML file. You can download the template from here. The following image shows the invoice template.
It’s also possible to pass some additional parameters — like the page size, orientation, and margins. Add the options(opens in a new tab) parameter to do this:
options = { 'page-size': 'Letter', 'orientation': 'Landscape', 'margin-top': '0.75in', 'margin-right': '0.75in', 'margin-bottom': '0.75in', 'margin-left': '0.75in', 'encoding': "UTF-8", 'custom-header': [ ('Accept-Encoding', 'gzip') ], 'no-outline': None}
pdfkit.from_file('index.html', 'index.pdf', options=options)Adding headers and footers
Use header-html and footer-html in the options dict to attach HTML files as repeating headers and footers on every page:
import pdfkit
options = { 'header-html': 'header.html', 'footer-html': 'footer.html', 'page-size': 'A4', 'margin-top': '1in', 'margin-right': '1in', 'margin-bottom': '1in', 'margin-left': '1in', 'encoding': "UTF-8"}
pdfkit.from_url('https://example.com', 'output_with_headers_footers.pdf', options=options)More use cases
Here are some common scenarios where HTML-to-PDF conversion with pdfkit is useful, with example code for each.
Generating reports
If you need to generate reports from web data, you can convert HTML tables or dashboards to PDF for easy sharing and archiving:
import pdfkit
html_report = """<html> <head><title>Report</title></head> <body> <h1>Monthly Sales Report</h1> <table border="1"> <tr><th>Product</th><th>Quantity</th><th>Price</th></tr> <tr><td>Product A</td><td>10</td><td>$100</td></tr> <tr><td>Product B</td><td>5</td><td>$200</td></tr> </table> </body></html>"""
pdfkit.from_string(html_report, 'report.pdf') 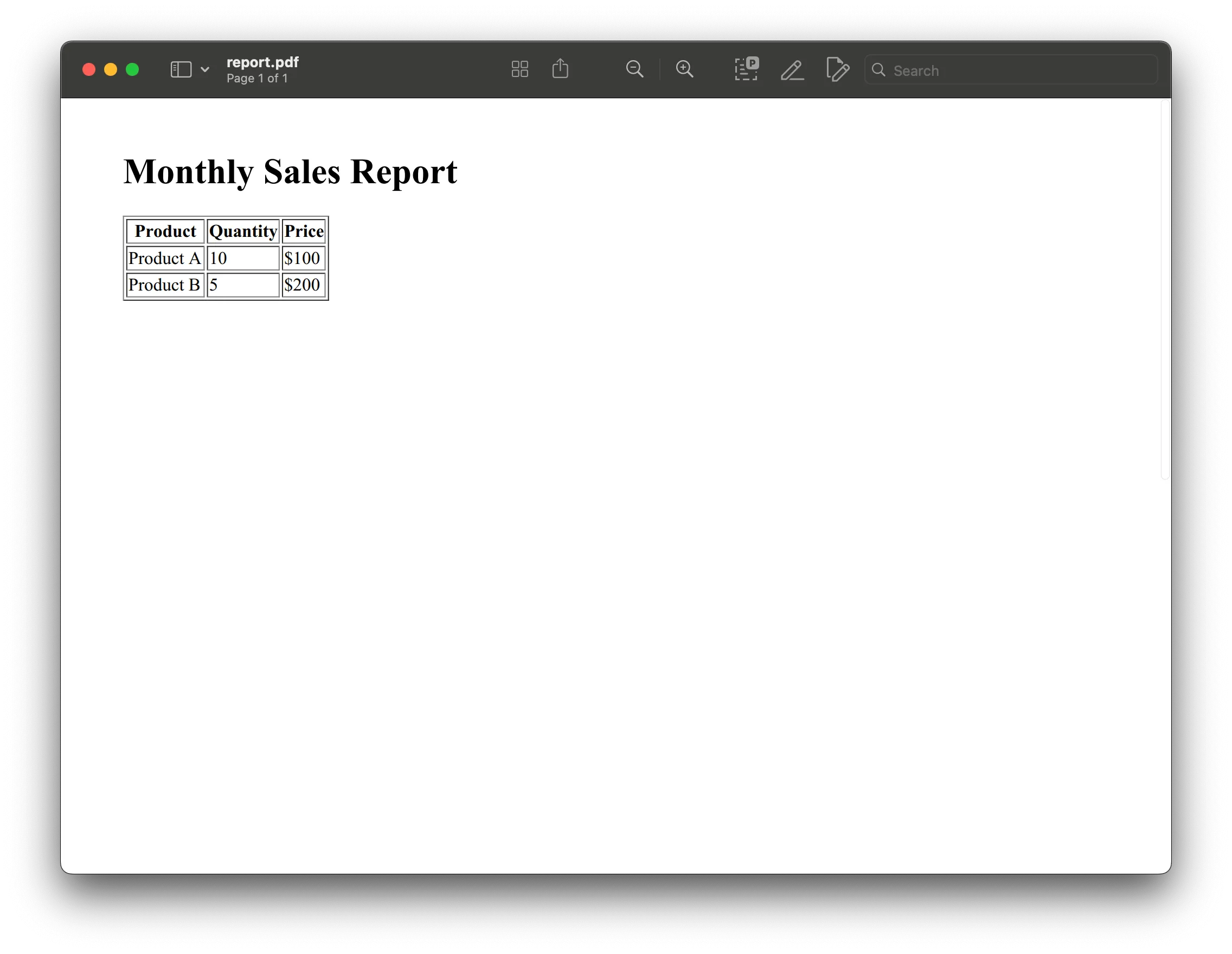
Creating printable event tickets
Convert dynamically generated HTML event tickets into PDFs that users can print or store digitally:
import pdfkit
event_ticket = """<html> <head><title>Event Ticket</title></head> <body> <h1>Concert Ticket</h1> <p>Date: 2026-09-15</p> <p>Venue: Music Hall</p> <p>Seat: A12</p> <p>Confirmation: 1234567890</p> </body></html>"""
pdfkit.from_string(event_ticket, 'ticket.pdf') 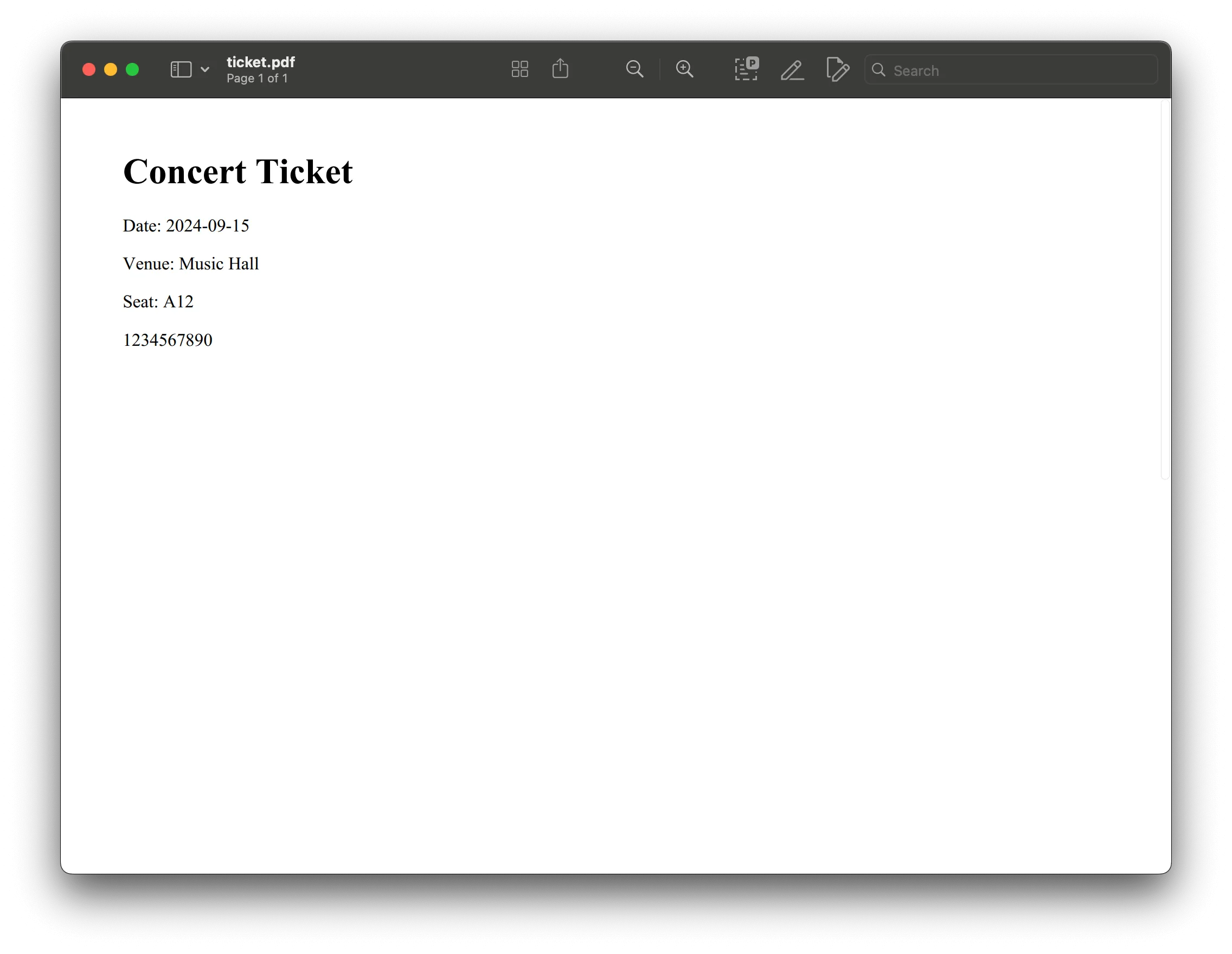
Exporting blog posts to PDF
If you’re running a blog and want to offer readers the option to download posts as PDFs, you can convert the HTML content of a post into a PDF:
import pdfkit
blog_post_html = """<html> <head><title>My Blog Post</title></head> <body> <h1>How to Use Python for Web Development</h1> <p>Python is a versatile language...</p> <h2>Getting Started</h2> <p>To start developing web applications with Python...</p> </body></html>"""
pdfkit.from_string(blog_post_html, 'blog_post.pdf') 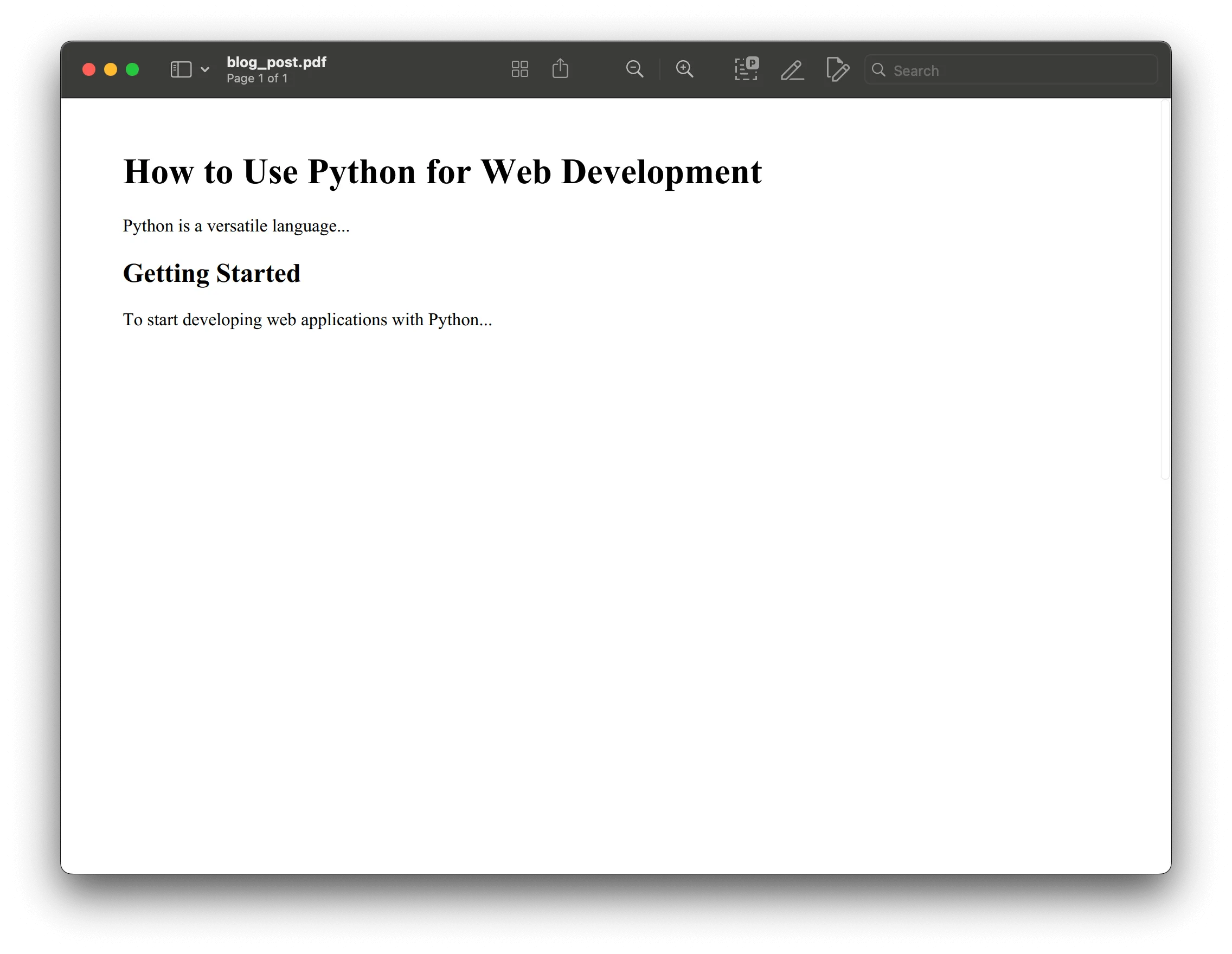
Invoice generation with data integration
Combine Python’s data processing capabilities with HTML-to-PDF conversion to generate invoices automatically:
import pdfkit
customer_name = "John Doe"items = [ {"name": "Product 1", "quantity": 2, "price": 50}, {"name": "Product 2", "quantity": 1, "price": 150},]
total = sum(item["quantity"] * item["price"] for item in items)
invoice_html = f"""<html> <head><title>Invoice</title></head> <body> <h1>Invoice for {customer_name}</h1> <table border="1"> <tr><th>Item</th><th>Quantity</th><th>Price</th></tr> {''.join(f"<tr><td>{item['name']}</td><td>{item['quantity']}</td><td>${item['price']}</td></tr>" for item in items)} <tr><td colspan="2">Total</td><td>${total}</td></tr> </table> </body></html>"""
pdfkit.from_string(invoice_html, 'invoice.pdf') 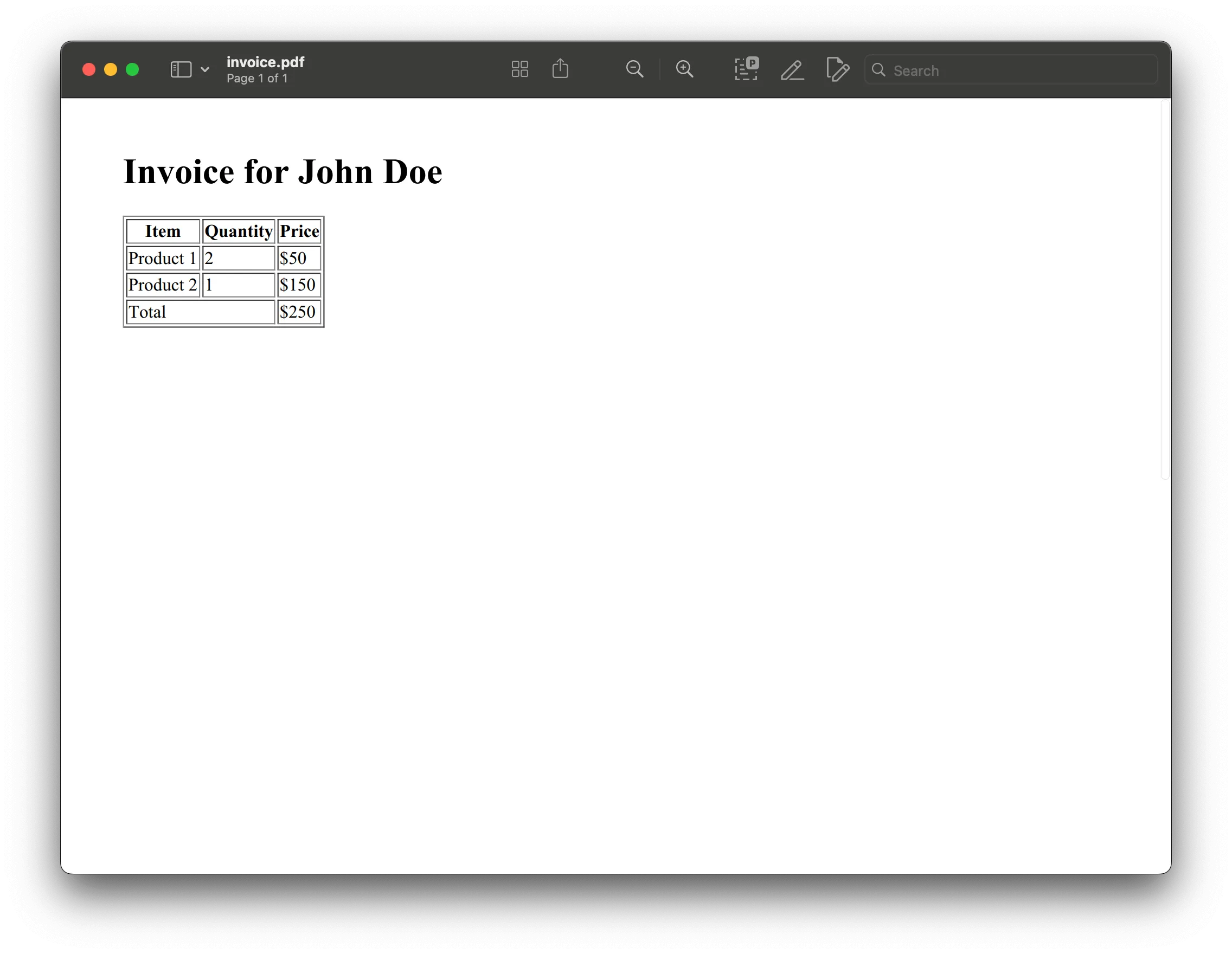
PDFs for e-learning materials
Create downloadable PDFs for e-learning courses, where the content is initially written in HTML:
import pdfkit
course_material = """<html> <head><title>Python Programming Course</title></head> <body> <h1>Introduction to Python</h1> <p>Python is a powerful, easy-to-learn programming language...</p> <h2>Lesson 1: Variables</h2> <p>Variables in Python are...</p> </body></html>"""
pdfkit.from_string(course_material, 'python_course.pdf') 
PDFs for product catalogs
Convert product catalogs stored as HTML into PDFs for distribution to clients or for offline viewing:
import pdfkit
catalog_html = """<html> <head><title>Product Catalog</title></head> <body> <h1>Our Products</h1> <div><h2>Product A</h2><p>Description of Product A...</p></div> <div><h2>Product B</h2><p>Description of Product B...</p></div> </body></html>"""
pdfkit.from_string(catalog_html, 'catalog.pdf') 
Multipage PDF creation
You can create a multipage PDF by concatenating several HTML strings:
import pdfkit
pages = [ "<html><body><h1>Page 1</h1><p>Content for page 1...</p></body></html>", "<html><body><h1>Page 2</h1><p>Content for page 2...</p></body></html>", "<html><body><h1>Page 3</h1><p>Content for page 3...</p></body></html>"]
pdfkit.from_string("".join(pages), 'multi_page.pdf') 
Common wkhtmltopdf gotchas
IOError: 'No wkhtmltopdf executable found'— The binary isn’t on yourPATH. Either add it, or pass an explicit configuration:pdfkit.from_file('in.html', 'out.pdf', configuration=pdfkit.configuration(wkhtmltopdf='/usr/local/bin/wkhtmltopdf')).- Local images and CSS don’t render — Pass
'enable-local-file-access': Noneinoptionsso wkhtmltopdf can read files from disk. - JavaScript-rendered content is missing — wkhtmltopdf executes JavaScript via Qt WebKit but with a short default delay. Use
'javascript-delay': 1000(ms) to wait for scripts. - Fonts look wrong on Linux servers — Install the fonts your HTML references (e.g.
fonts-liberation) before generating; wkhtmltopdf can’t fetch them at runtime.
Conclusion
You now have a working HTML-to-PDF pipeline in Python using wkhtmltopdf and pdfkit — enough for invoices, reports, and other static documents.
When the toolchain starts to bite — complex CSS, JavaScript-heavy pages, missing fonts on a server, or simply the maintenance risk of two deprecated dependencies — Nutrient’s HTML-to-PDF API is a drop-in REST replacement that needs no binary install. For in-browser viewing, annotation, and signing, the Nutrient JavaScript PDF library integrates with React.js, Angular, and Vue.js. Start a free trial or launch the demo.
FAQ
To convert HTML to PDF using Python with wkhtmltopdf, install pdfkit with pip install pdfkit. Then use pdfkit.from_file('input.html', 'output.pdf') to generate a PDF.
First, install wkhtmltopdf on your system and ensure it’s in your PATH. Then, install pdfkit using pip install pdfkit and configure it in your Python script if needed.
Yes, you can customize the PDF output by passing options like page size and margins to the pdfkit function when converting HTML to PDF with Python.
Review the error messages, ensure wkhtmltopdf is correctly installed, verify that HTML resources are accessible, and adjust pdfkit options to address rendering issues.