| Best for document type | Digitally born PDFs with fixed templates — invoices,
receipts, forms where layout is consistent | Scanned documents or non-digitally born content — handwritten
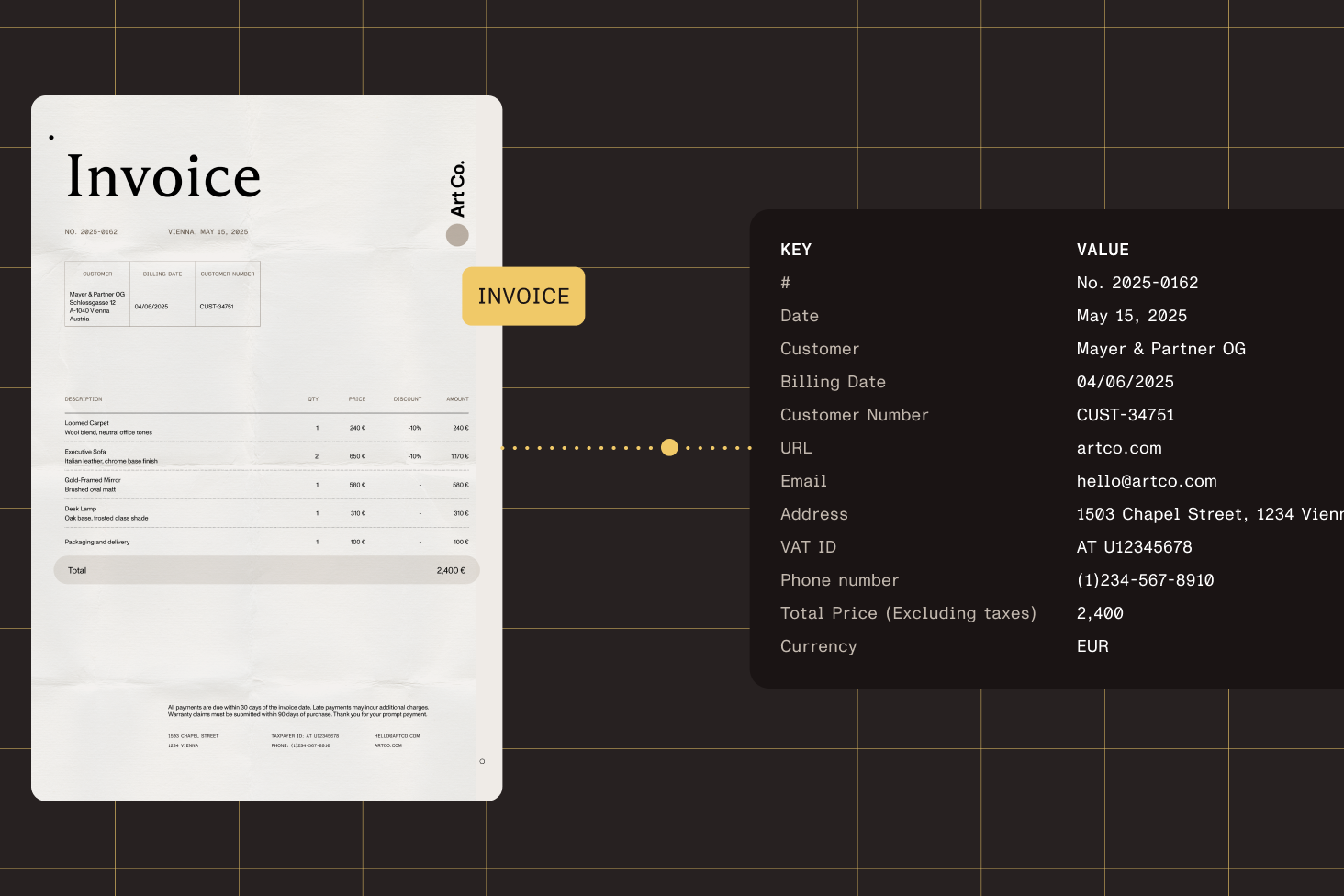
forms, research papers, variable layouts | Documents requiring classification and extraction — invoices,
resumes, passports with varying formats |
| Platform availability | All platforms: Web, .NET, Python, Java, iOS, Android,
Document Engine | Python and Java SDKs only | .NET 8.0+ only |
| Processing mode | Text extraction only — converts images to searchable text
with minimal overhead | Intelligent content recognition (ICR) — local AI models or
optional cloud VLM enhancement | Hybrid LLM + key-value pair — on-premises classification and
extraction |
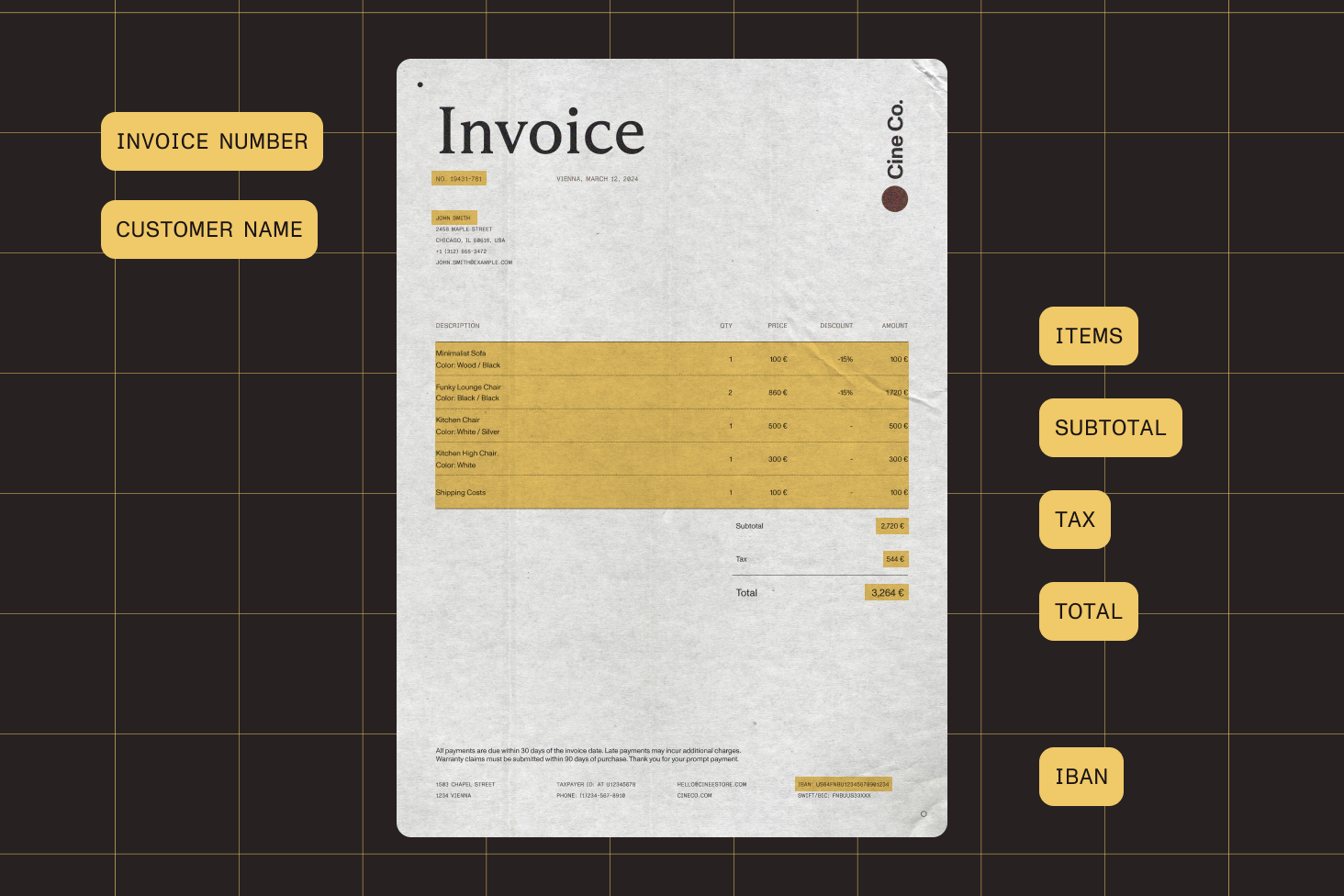
| Key capabilities | 120+ languages, zonal OCR, preprocessing (deskew, noise
reduction), throughput-optimized | Table extraction with cell boundaries, handwriting
recognition, equation detection (LaTeX), document structure
analysis | 10 preconfigured templates, automated document
classification, structured data extraction, custom template
builder |
| Template requirements | Best with fixed templates — use Document Engine + Viewer if
you control PDF creation | No templates required — handles variable layouts and
unstructured content | Works with or without templates — 10 built-in templates adapt
to format variations |
| When to use | You control PDF creation or the document follows a fixed
template — high-volume batches where speed is priority | Content isn’t digitally born or no fixed template exists —
need semantic understanding of document structure | Need classification and extraction in one step — processing
mixed document types at scale |
| Language support | 120+ languages (Document Engine) — most comprehensive
coverage in industry | Multilingual support via AI models — handles mixed-language
documents | Multilingual via LLM — optimized for common business
documents |
| Deployment options | Fully on-premises — no external API calls required | Local ICR for privacy or cloud VLM for accuracy — flexibility
to balance compliance vs. performance | Fully on-premises with .NET runtime — meets HIPAA, SOC 2,
air-gapped requirements |
| Ideal use cases | Invoice batches, receipt scanning, search indexing,
high-volume text extraction | Forms with handwriting, research papers with equations,
complex tables, scanned documents | Automated invoice processing, resume parsing, passport
extraction, mixed document workflows |