




How to convert PDF to JPG using Python
Table of contents

This tutorial shows how to convert PDFs to JPG images using Nutrient’s Python API. You’ll create a free account, get API credentials, and write a Python script to convert documents. The API also supports merging, watermarking, and page manipulation before conversion.
Convert PDF files to JPG images using Nutrient’s PDF-to-JPG Python API. The free plan includes 200 credits. Different operations use different amounts of credits, so your document count will vary. Create a free account(opens in a new tab) to get your API key.
Why convert PDF to JPG?
Converting PDF files to JPG is essential for workflows requiring image formats. Common use cases include:
- Web optimization — Convert PDFs to JPG for faster page loading and better web compatibility, especially for document previews and galleries.
- Thumbnail generation — Create preview images for document management systems, file browsers, and content libraries.
- Image processing pipelines — Extract pages as images for OCR, computer vision analysis, or machine learning workflows.
- Social media sharing — Convert documents to shareable image formats for platforms that don’t support PDF embedding.
- Archive and preview — Generate lightweight previews of PDF documents without requiring full PDF rendering capabilities.
The PDF-to-JPG API automates this process in your workflow.
Nutrient DWS Processor API
Converting PDF to JPG is one of 30+ operations available through our PDF API tools. Combine PDF-to-JPG conversion with other tools for complex workflows:
- Converting various file formats and extracting pages as images
- Converting PDFs to images after watermarking and flattening
- Processing PDFs with page manipulation before image export
Your account includes access to all PDF API tools.
Step 1 — Creating a free account on Nutrient
Go to our website(opens in a new tab) to create your free account.
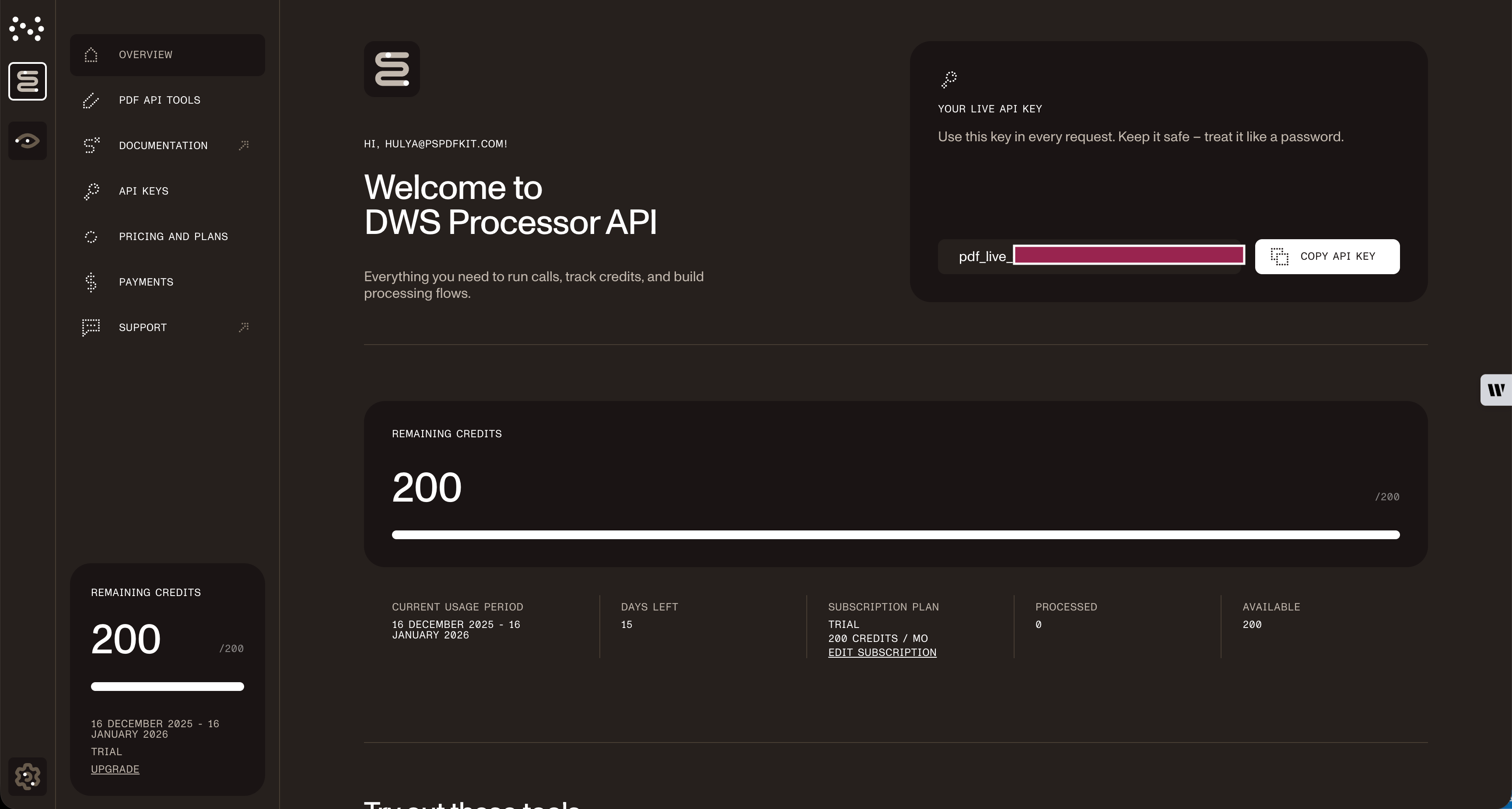
After creating your account, you’ll see your plan overview.
You start with 200 credits and access to all PDF API tools.
Step 2 — Obtaining the API key
After verifying your email, get your API key from the dashboard. Click API keys in the left menu to view your keys.
Copy the Live API key for the PDF-to-JPG API.
Step 3 — Setting up folders and files
Create a folder called pdf_to_jpg and open it in a code editor. This tutorial uses VS Code. Create two folders inside pdf_to_jpg: input_documents and processed_documents.
Copy your PDF file to the input_documents folder and rename it to document.pdf. Use our demo document if needed.
In the root folder, pdf_to_jpg, create a file called processor.py for your code.
Your folder structure:
pdf_to_jpg├── input_documents| └── document.pdf├── processed_documents└── processor.pyStep 4 — Writing the code
Open the processor.py file and paste the code below into it:
import requestsimport json
response = requests.request( 'POST', 'https://api.nutrient.io/build', headers = { 'Authorization': 'Bearer YOUR_API_KEY_HERE' }, files = { 'document': open('input_documents/document.pdf', 'rb') }, data = { 'instructions': json.dumps({ 'parts': [ { 'file': 'document' } ], 'output': { 'type': 'image', 'format': 'jpg', 'dpi': 500 } }) }, stream = True)
if response.ok: with open('processed_documents/image.jpg', 'wb') as fd: for chunk in response.iter_content(chunk_size=8096): fd.write(chunk)else: print(response.text) exit()Make sure to replace YOUR_API_KEY_HERE with your API key.
Code explanation
Import the requests and json dependencies. Create the instructions for the API call.
Use the requests module to make the API call. Store the result in the processed_documents folder.
Output
Run the code:
python3 processor.pyAfter execution, you’ll find image.jpg in the processed_documents folder.
The folder structure becomes:
pdf_to_jpg├── input_documents| └── document.pdf├── processed_documents| └── image.jpg└── processor.pyAdditional resources
Explore more ways to work with Nutrient API:
- Postman Collection — Test API endpoints directly in Postman
- Zapier Integration — Automate document workflows without code
- MCP Server — PDF automation for LLM applications
- Python client — Official Python library for Nutrient API
Conclusion
You learned how to convert PDFs to JPG images using our Python API.
Integrate these functions into your existing applications. The same API token works for other operations like merging documents and adding watermarks. Sign up(opens in a new tab) for a free trial.
FAQ
Yes. The API maintains high image quality during conversion. You can control output quality using the dpi parameter (shown as 500 in the example). Higher DPI values create larger files with better quality. Standard web images use 72–150 DPI, while print requires 300+ DPI.
Python 3.6+ is required. The tutorial uses the requests library (install with pip install requests). The json module is built into Python. No additional PDF processing libraries, like PyPDF2 or pdf2image, are needed.
Yes. The Nutrient Python client provides a higher-level interface for API operations. While this tutorial uses direct HTTP requests with the requests library for transparency, the Python client simplifies authentication, error handling, and response parsing for production applications.


