




From PDF to spreadsheet: The impossible conversion
Table of contents
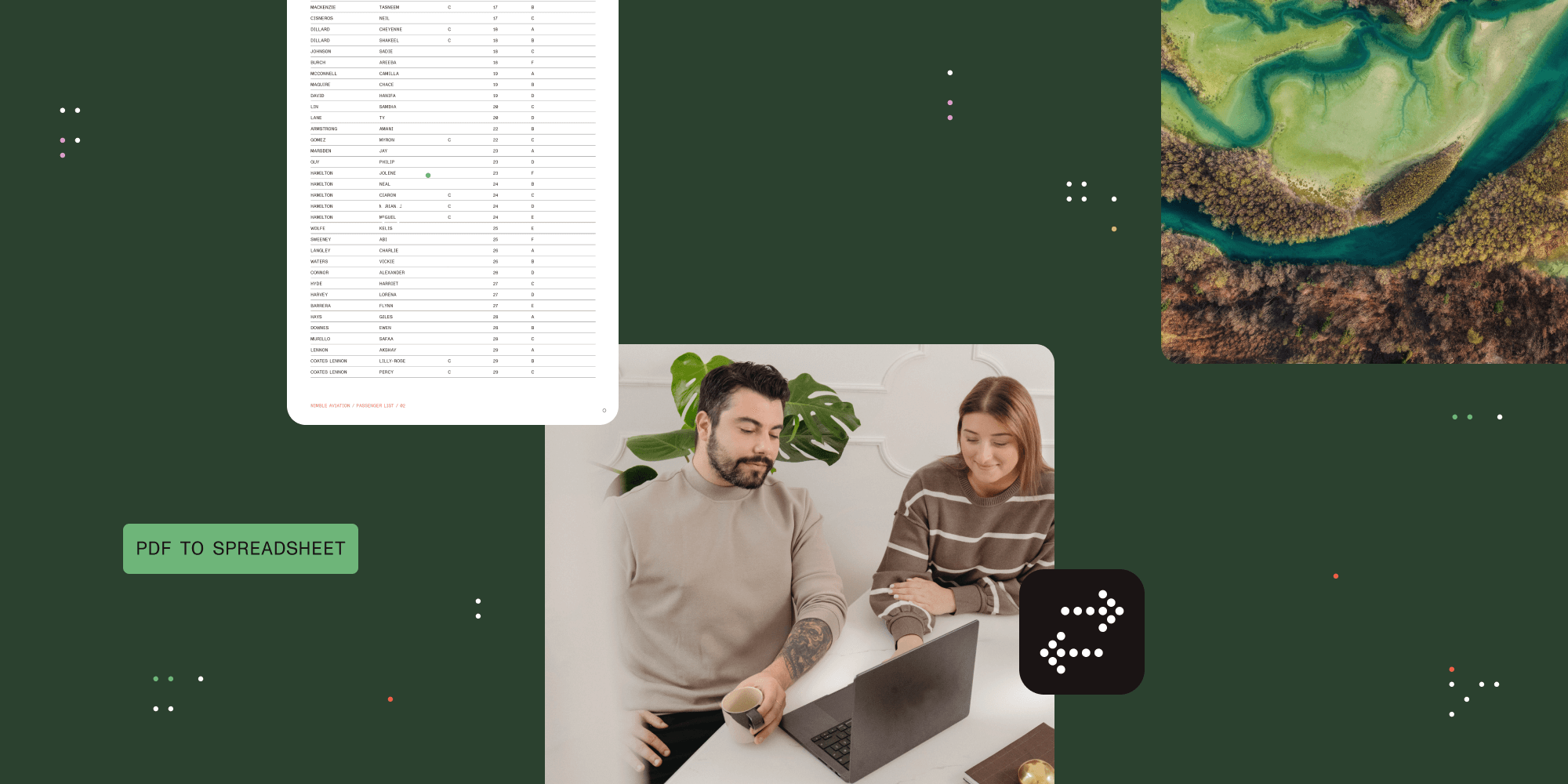
This article explores why converting spreadsheets to PDFs is straightforward, while the reverse process presents significant challenges. It examines the fundamental differences between structured formats (spreadsheets, Word documents, slide documents) and fixed-layout formats (PDFs, printed pages, static images). Additionally, it demonstrates how modern solutions like Nutrient can significantly improve accuracy, and why even imperfect conversions provide tremendous value by giving users a strong starting point that saves hours of manual data entry.
Have you ever tried to convert a PDF table into a spreadsheet and wondered why the results are often disappointing? Or perhaps you’ve noticed that converting a spreadsheet to a PDF works flawlessly, but going the other direction is fraught with errors and formatting issues? The reason lies in the fundamental architectural differences between these two document types.
Nutrient saves you hours of manual work by extracting tables directly into spreadsheets.
Understanding document structures
To understand why PDF-to-spreadsheet conversion is so challenging, it’s important to examine how these documents store and represent information.
Spreadsheets: Structured data with semantic meaning
Spreadsheets are structured formats built around a logical grid system. Every piece of data in a spreadsheet has:
- Explicit cell coordinates, such as A1, B2, C3, etc.
- Semantic meaning through column headers and data types
- Hierarchical organization with sheets, rows, and columns
When you enter Q1 in cell A1 and Q2 in cell B1, the spreadsheet knows these are related pieces of information in the same row. The structure is inherent and meaningful.
PDFs: Fixed-layout formats
PDFs, on the other hand, are fixed-layout formats designed for consistent visual presentation. A PDF stores:
- Absolute coordinates for text and graphics (x: 120px, y: 350px)
- Visual formatting information (font, size, color)
- Layout-focused structure optimized for printing and viewing
When a PDF displays Q1 at position (120, 350) and Q2 at position (250, 350), there’s no encoded relationship between these elements. They’re simply visual objects placed on a page.
Why spreadsheet-to-PDF conversion works perfectly
Converting from spreadsheet to PDF is straightforward because it involves moving from structure to presentation:
- Cell A1 contains Q1 → Place Q1 at coordinates (120, 350)
- Cell B1 contains Q2 → Place Q2 at coordinates (250, 350)
- Apply formatting rules → Font: Arial, Size: 12pt, Color: Black
- Maintain visual grid → Draw lines at appropriate coordinates
The structured data provides all the information needed to create a consistent visual layout.
PDF-to-spreadsheet challenges
Converting PDF back to spreadsheet requires recreating structure from pure visual information, a process fraught with ambiguity and interpretation challenges. Even humans often struggle to determine the original data structure when looking at a PDF, having to make educated guesses about cell boundaries, headers and footers, and data groupings that were clear in the original spreadsheet but lost in the visual conversion.
Challenge 1: Grid detection and cell boundaries
PDFs don’t store grid information; they only contain visual lines and text positions. Converting requires algorithms to infer grid structure from visual cues. Consider this PDF layout:
Department Q1 Q2 Q3 Q4 TotalSales 100 120 110 130 460Marketing 50 55 60 65 230Support 25 30 28 32 115The algorithm must determine:
- Are there six columns or twelve?
- Where do cell boundaries begin and end?
- Should Marketing align perfectly with Department or be offset?
- What happens if department names are longer than the column width?
Now, consider this more complex layout:
Department Q1 Budget Q1 Actual Variance Q2 BudgetSales Operations 100,000 98,500 -1,500 105,000Marketing & PR 50,000 52,100 +2,100 48,000Customer Support 25,000 24,800 -200 26,000Additional challenges emerge:
- Should Sales Operations be split across multiple cells or kept as one?
- How wide should each column be to accommodate varying text lengths?
- Should negative values like -1,500 be treated as separate elements?
Consider a PDF with merged cells, rotated text, or irregular spacing. A single table might have varying column widths, making automated grid detection extremely difficult.
Challenge 2: Managing grid complexity without breaking functionality
One of the most significant challenges is balancing accuracy with usability. Consider this scenario:
Table 1 and Table 2 (positioned differently on the same page)
Department Q1 Budget Q1 Actual Variance Q2 BudgetSales Operations 100,000 98,500 -1,500 105,000Marketing & PR 50,000 52,100 +2,100 48,000Customer Support 25,000 24,800 -200 26,000
Product Units Price Widget A 150 25.99 Widget B 200 15.50 Widget C 75 45.00The unified grid dilemma — To fit both tables in a single spreadsheet, the conversion algorithm faces an impossible choice.
Option 1: Single massive grid — Create a grid wide enough to accommodate both tables’ positioning and alignment. This results in:
- A sprawling grid with numerous empty columns between and around tables.
- Most cells serving no purpose other than spacing.
- Users having to navigate through vast empty areas to find actual data.
- A complex structure that’s difficult to understand and manipulate.
Option 2: Merged cell solution — Use merged cells to accommodate the different alignments:
- Table 2’s indented position requires merging cells A6–C6 to position Product correctly.
- Each subsequent row needs careful merging to maintain alignment.
- A grid so complex with merged cells that simple operations like sorting or filtering become impossible.
Option 3: Separate sheets — Place each table on different worksheets, losing the visual relationship that existed in the original PDF.
Option 4: Adjust positioning for simpler grid — Modify the table positions to create a cleaner layout.
- Move Table 2 to align with Table 1’s left margin.
- Place tables in adjacent columns or rows for better organization.
- You now have a more usable spreadsheet, but the spatial relationships from the original PDF are completely lost
Each solution destroys some aspect of the original document’s usefulness, demonstrating why the perfect conversion remains elusive.
Challenge 3: Distinguishing headers from data
Consider this scenario: A PDF contains the text Quarterly Financial Report positioned at the top of a page with data tables below. Is this text:
- The document title that should appear in the page header?
- A table title that belongs in the first row of the spreadsheet?
- A section header that should be placed in a separate cell above the data?
Without explicit markup, algorithms must guess based on:
- Font size and weight differences
- Positioning and spacing patterns
- Distance from surrounding data elements
- Document structure analysis
Real-world complexity — The same text, Quarterly Financial Report, could appear in three different contexts on the same PDF page — as a document header, as a table title, and as a footer reference — each requiring different treatment in the final spreadsheet.
Current limitations and future possibilities
Despite advances in AI and machine learning, perfect PDF-to-spreadsheet conversion remains elusive, due to the reasons outlined below.
Technical limitations
- OCR accuracy — Even advanced OCR makes errors with similar characters (0 vs O, 1 vs l).
- Layout analysis — Complex layouts with irregular spacing defeat pattern. recognition
- Context understanding — Semantic meaning requires domain knowledge that’s often absent from documents.
Fundamental impossibility
- Information loss — The conversion from structured to visual representation loses critical metadata.
- Ambiguity resolution — Multiple valid interpretations exist for the same visual layout.
- Human intent — The original creator’s intentions for data relationships aren’t encoded in PDFs.
Practical approaches and realistic expectations
While perfect conversion isn’t possible, modern tools can achieve good results by following the approaches below.
Setting realistic goals
- Accept imperfection — Focus on extracting the majority of data accurately.
- Manual review process — Build workflows that expect human verification.
- Iterative improvement — Use feedback to train better conversion algorithms.
Intelligent grid placement solutions
Nutrient’s modern conversion tools tackle the grid detection challenge through intelligent content analysis:
- Content-aware grid generation — Instead of imposing a rigid grid structure, the system analyzes text positioning and creates flexible grids that wrap around actual content.
- Contextual cell merging — When text spans multiple potential cells, the system intelligently determines whether to merge cells or split content based on semantic context.
Example approach — Rather than creating a 20×15 grid that results in hundreds of empty cells, the system might detect three distinct data regions and create appropriately sized grids around each, preserving the logical structure while minimizing complexity.
The value of “good enough” conversion
While perfect PDF-to-spreadsheet conversion remains impossible, even imperfect results provide substantial practical value, outlined below.
Time savings and productivity gains
Consider a financial analyst working with a 50-page quarterly report PDF containing dozens of data tables. Manual data entry would require:
- 8–12 hours of tedious copying and pasting
- High error rates from manual transcription
- Formatting inconsistencies across different sections
An automated conversion, even at 80 percent accuracy, provides:
- Initial data structure in minutes instead of hours
- Consistent formatting that can be refined systematically
- Bulk processing capability for multiple documents
Strategic advantages of starting points
Faster iteration cycles — Teams can quickly extract data, identify issues, and refine extraction rules rather than starting from scratch each time.
Scalability — What takes one person a full day to extract manually can be processed across hundreds of documents automatically, with human review focused only on verification and cleanup.
Conclusion
The next time you see PDF-to-Excel converter software promising perfect results, remember the fundamental challenge: You’re asking an algorithm to reverse-engineer structure from pure visual presentation. While spreadsheet-to-PDF conversion follows clear rules and produces predictable results, the reverse journey requires interpretation, inference, and often a degree of luck.
Understanding these limitations helps set appropriate expectations and choose the right tools for your needs. Sometimes the best approach is to keep your data in structured formats from the beginning, using PDFs only for their intended purpose: beautiful, consistent visual presentation.
The impossible conversion teaches us something important about document design: Structure matters, and once you give it up for visual perfection, getting it back is far more challenging than you might expect.
Perfect PDF-to-Excel conversion doesn’t exist — but getting 80 percent of the work done in seconds is a game-changer. See how Nutrient makes it possible.


