




Rich text PDF annotations: Managing XHTML and annotation property synchronization
Table of contents
- PDF specification — Rich text annotations use dual-format storage (XHTML content and annotation properties) for maximum compatibility across viewers.
- Synchronization challenge — XHTML content and annotation properties can become inconsistent, breaking UI state and cross-platform exports.
- Intelligent solution — Automatic bidirectional synchronization detects uniform styling and extracts properties while preserving complex formatting.
- Key insight — Success lies in making XHTML/property synchronization invisible to developers while ensuring consistent behavior everywhere.
Rich text PDF annotations look simple — just format text and save it to a PDF. But building robust implementations reveals complex challenges: synchronizing XHTML content with annotation properties, handling paste operations from Microsoft Word, and maintaining consistency across iOS, Android, and web platforms.
At Nutrient, we’ve learned that success lies not in building another rich text editor, but in creating intelligent synchronization that makes these complexities invisible to developers. Get this right, and developers focus on their application logic while the system automatically handles HTML cleanup, property extraction, and cross-platform compatibility.
Implement robust rich text PDF annotations with automatic XHTML and property synchronization today.
Plain text vs. rich text: Understanding the fundamentals
Before diving into synchronization challenges, it’s important understand the two text format approaches PDF annotations support: plain text format and rich text format.
Plain text format:
const annotation = new TextAnnotation({ text: { format: 'plain', value: 'Hello World' }, fontColor: Color.fromHex('#ff0000'), fontSize: 14, isBold: true})Plain text applies formatting uniformly, meaning every character gets the same color, size, and style. This approach offers maximum compatibility and performance.
Rich text format (XHTML):
const annotation = new TextAnnotation({ text: { format: 'xhtml', value: '<p><span style="color: #ff0000; font-size: 14pt; font-weight: bold">Hello World</span></p>' }, // Properties must stay synchronized with XHTML content. fontColor: Color.fromHex('#ff0000'), fontSize: 14, isBold: true})Rich text enables granular formatting, which means individual words can have different colors, sizes, and styles within the same annotation.
When to use each format
Use plain text when:
- You need maximum compatibility across all PDF viewers
- Simple, uniform styling is sufficient
- You’re building basic markup functionality
Use rich text when:
- You need granular formatting control within annotations
- Users require advanced text styling capabilities
- You’re building collaborative review workflows
Rich text in the PDF specification
Understanding how the PDF specification (ISO 32000) handles rich text is crucial for building robust annotation systems. The specification defines specific requirements that ensure cross-platform compatibility and consistent rendering across different PDF viewers.
PDF annotation text storage architecture
The PDF specification stores rich text annotation content using a dual-format approach, outlined below.
Rich text value (/RV entry) — Full XHTML markup stored in the annotation dictionary:
<body xmlns="http://www.w3.org/1999/xhtml" xmlns:xfa="http://www.xfa.org/schema/xfa-data/1.0/" xfa:spec="2.0.2"> <p><span style="color: #ff0000; font-size: 14pt; font-weight: bold">Formatted text</span></p></body>Annotation properties — Individual formatting properties in the PDF dictionary for compatibility:
/Contents (Hello World)/DA (/Helv 14 Tf 1 0 0 rg) % Default appearance string/RC (...XHTML content...) % Rich text contentsXHTML markup and appearance streams
Modern PDF annotation systems rely on the rich text value (/RV entry), i.e. XHTML markup stored in the annotation dictionary serves as the source for generating appearance streams. This approach ensures consistent rendering across different PDF viewers.
Required namespace declarations for compatibility:
xmlns="http://www.w3.org/1999/xhtml"xmlns:xfa="http://www.xfa.org/schema/xfa-data/1.0/"xfa:spec="2.0.2"XHTML subset support — The PDF specification requires compatibility with a restricted subset of XHTML 1.0, including:
| Element | Purpose | Attributes supported |
|---|---|---|
<body> | Root container | xmlns, xmlns:xfa, xfa:spec |
<p> | Paragraph blocks | style |
<span> | Inline styling | style |
<b>, <strong> | Bold formatting | - |
<i>, <em> | Italic formatting | - |
<u> | Underline formatting | - |
For detailed information about compatible XHTML markup and implementation examples, refer to our rich text annotations guide.
Supported CSS properties per PDF specification
The PDF specification restricts CSS properties to ensure consistent rendering across viewers, as outlined in the following table.
| Property | Values | PDF spec requirements |
|---|---|---|
color | Hex colors | Must be valid RGB hex values |
background-color | Hex colors | Optional for text highlighting |
font-family | Font names | Must fall back to standard PDF fonts |
font-size | Points or pixels | Converted to points for PDF storage |
font-weight | normal, bold | Binary bold state only |
font-style | normal, italic | Binary italic state only |
text-decoration | none, underline | Limited decoration support |
Cross-platform compatibility requirements
The PDF specification ensures that rich text annotations work consistently across different platforms:
Adobe Acrobat compatibility — Annotations must validate against XFA schemas and use only approved XHTML elements and CSS properties.
Mobile viewer fallbacks — When XHTML parsing is limited, viewers can fall back to annotation-level properties for basic formatting.
Export format preservation — XFDF and other interchange formats prioritize annotation properties over XHTML content, making synchronization crucial.
The synchronization challenge
Now that you understand how the PDF specification handles rich text storage, here’s where the implementation gets complex. This dual-format approach creates a critical synchronization challenge:
- XHTML content — Detailed styling information for advanced PDF viewers
- Annotation properties — Simplified formatting for compatibility with mobile SDKs and legacy viewers
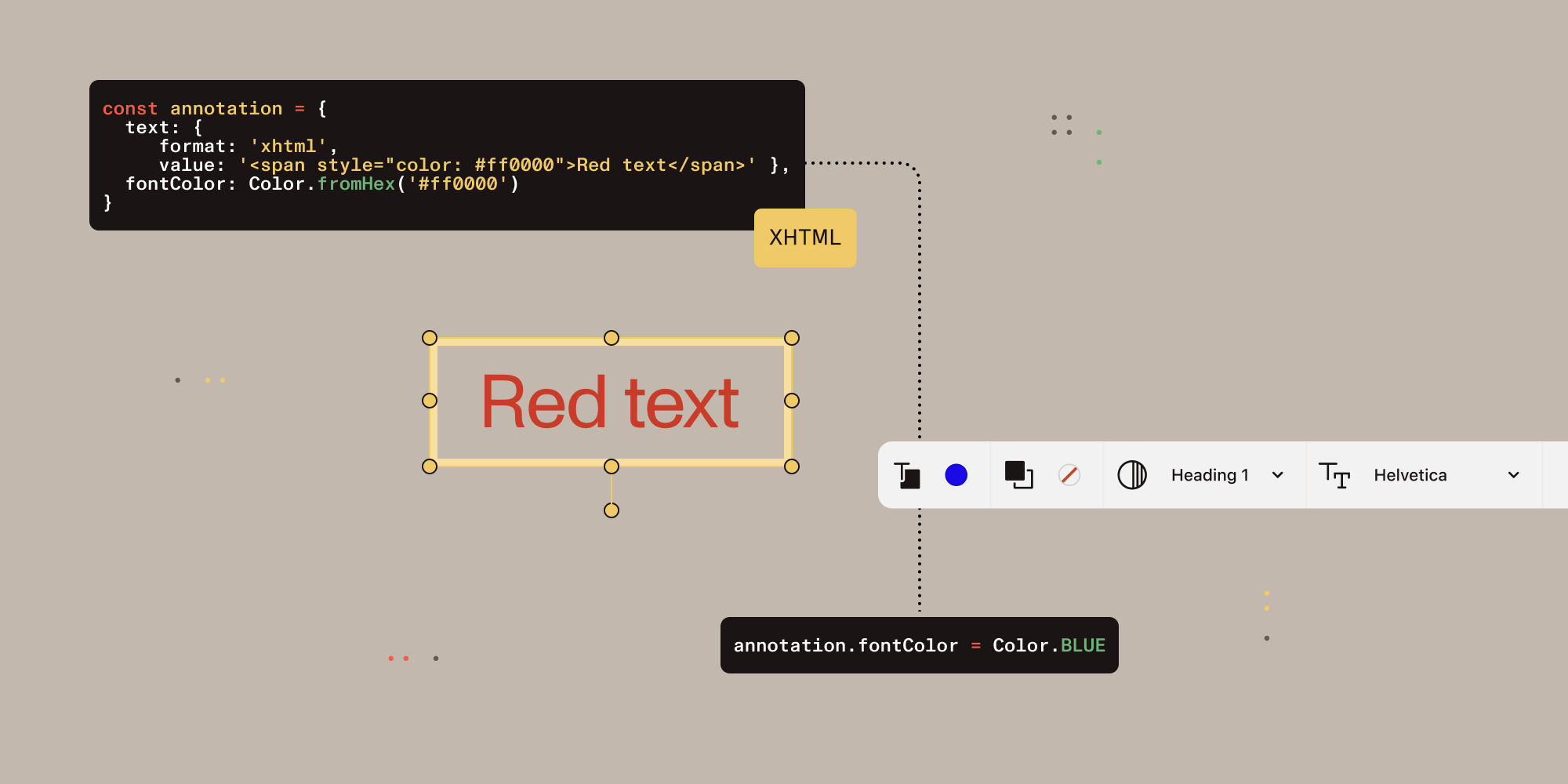
Consider this scenario where they become unsynchronized:
// Initial state: Both XHTML and properties show red text.const annotation = { text: { format: 'xhtml', value: '<span style="color: #ff0000">Red text</span>' }, fontColor: Color.fromHex('#ff0000') // Synchronized}
// Developer updates the property programmatically.annotation.fontColor = Color.BLUE// But XHTML content still contains: <span style="color: #ff0000">Red text</span>
// Result: Inconsistent state that breaks UI state synchronization.This synchronization problem (and its solution) can be visualized as follows:
THE PROBLEM: Inconsistent state after developer update +---------------------------------+ +---------------------------------+ | XHTML content | | Annotation properties | | | X | | | <span style="color: #ff0000"> | | fontColor: Color.BLUE | | Red text | | fontSize: 14 | | </span> | | isBold: false | +---------------------------------+ +---------------------------------+ | | v v [ Renders RED text ] [ UI toolbar shows BLUE ]
USER SEES CONFUSING MISMATCH!
THE SOLUTION: Intelligent synchronization +---------------------------------+ +---------------------------------+ | XHTML content | | Annotation properties | | | <==> | | | <span style="color: #0000ff"> | | fontColor: Color.BLUE | | Blue text | | fontSize: 14 | | </span> | | isBold: false | +---------------------------------+ +---------------------------------+ | | v v [ Renders BLUE text ] [ UI toolbar shows BLUE ]
CONSISTENT STATE!This creates several problems:
- UI state inconsistency — Toolbar shows blue color while text renders as red, confusing users
- Export compatibility issues — XFDF exports may only recognize annotation properties, losing rich formatting
- Cross-platform variations — Same annotation appears differently on iOS, Android, and web platforms
This creates a fundamental challenge: the need for formatting fidelity for advanced viewers while maintaining compatibility for basic ones. But the solution isn’t choosing between XHTML and annotation properties — it’s intelligently using both.
Nutrient’s intelligent synchronization solution
Instead of treating rich text as a black box, Nutrient Web SDK implements intelligent bidirectional synchronization that automatically manages the relationship between XHTML content and annotation properties.
Automatic property extraction
When you create or modify rich text annotations, the system automatically analyzes the content and synchronizes properties.
Uniform styling detection:
// User creates content with consistent styling.const annotation = new TextAnnotation({ text: { format: 'xhtml', value: '<p><span style="color: #0000ff; font-weight: bold">All blue bold text</span></p>' }})
// System automatically extracts uniform properties:// annotation.fontColor = Color.fromHex('#0000ff')// annotation.isBold = trueMixed formatting preservation:
// User creates content with varied styling.const annotation = new TextAnnotation({ text: { format: 'xhtml', value: '<p><span style="color: #ff0000">Red</span> and <span style="color: #0000ff; font-weight: bold">blue bold</span></p>' }})
// System preserves complexity in XHTML, uses defaults for properties:// annotation.fontColor = Color.BLACK (default fallback)// annotation.isBold = false (mixed state)This approach ensures:
- Optimal compatibility — Uniform styling extracted for better cross-platform support
- Formatting preservation — Complex mixed formatting maintained in XHTML
- Performance optimization — Annotation properties enable faster rendering
- Developer simplicity — No manual property management required
Bidirectional synchronization
The system handles updates from multiple sources, ensuring consistency regardless of how changes are made:
User edits rich text — When users modify formatting in the rich text editor, the system automatically updates the XHTML content and extracts any uniform properties from the annotation level.
Programmatic property changes — When developers modify annotation properties via API, the system automatically updates XHTML content to match.
Content paste operations — When users paste from external sources like Microsoft Word or Google Docs, the system automatically cleans up proprietary HTML formatting, converts to PDF-compliant XHTML structure, and analyzes for property extraction.
Cross-platform export benefits
Cross-platform export benefits are most apparent when the exported format must preserve both appearance and annotation properties. XFDF, as a common interchange format, illustrates how synchronization ensures consistent formatting across different viewers.
XFDF compatibility
One of the biggest advantages of proper synchronization becomes apparent when exporting annotations for cross-platform use:
// Export annotation to XFDF format.const xfdfData = await instance.exportXFDF()
// XFDF primarily uses annotation properties, not XHTML:// <text color="#FF0000" fontsize="14" flags="print">Hello World</text>Without synchronized annotation properties, rich text annotations would lose their formatting when exported to XFDF, appearing as plain black text in target applications.
Getting started with rich text annotations
With the synchronization concepts established, the next step is implementation. Getting started with rich text annotations begins by ensuring the environment is properly configured.
Prerequisites
First, enable rich text support when loading your document:
NutrientViewer.load({ // ...other configuration enableRichText: () => true});Basic implementation
Nutrient Web SDK makes rich text annotation implementation straightforward:
// Create a rich text annotation — synchronization is automatic.const annotation = new NutrientViewer.Annotations.TextAnnotation({ pageIndex: 0, boundingBox: new NutrientViewer.Geometry.Rect({ left: 100, top: 100, width: 200, height: 50 }), text: { format: 'xhtml', value: '<p><span style="color: #0000ff; font-weight: bold">Blue bold text</span></p>' }})
// Add to document — properties automatically synchronized.instance.create(annotation)Best practices
- Use plain text format for simple, uniformly formatted content to maximize compatibility
- Use rich text format when you need mixed formatting within the same annotation
- Let the system handle synchronization to avoid manually managing both XHTML and properties
- Test with real clipboard data from Word, Google Docs, and other common sources
- Consider your export targets; XFDF and mobile platforms benefit from synchronized annotation properties
Conclusion
Building robust rich text PDF annotations requires more than a rich text editor — it demands intelligent synchronization between XHTML content and annotation properties. The key insights from Nutrient’s approach:
- Treat synchronization as a first-class concern, not an afterthought
- Use the right format for the right purpose, i.e. plain text for simplicity, rich text for complexity
- Let the system handle property management, as automatic synchronization prevents inconsistencies
- Plan for real-world content, since users will paste from Word, Google Docs, and other sources
- Design for cross-platform compatibility, because XFDF and mobile platforms need annotation properties
The approaches outlined here form the foundation of Nutrient’s rich text annotation system, providing developers with a robust, reliable solution that handles the complexity behind the scenes.
Want to see this in action? Try Nutrient Web SDK with rich text annotations enabled, or explore our annotation documentation for implementation details.
Ready to implement rich text annotations with intelligent synchronization? Nutrient Web SDK provides battle-tested synchronization logic with cross-platform export, intelligent paste handling, and comprehensive error recovery built in.


