Make your documents searchable, selectable, and ready for extraction using powerful OCR tools — available through the Web SDK with Document Engine or our C# .NET OCR library.
Turn scanned PDFs and image files into fully searchable, selectable documents with embedded text layers — ideal for indexing, compliance, and downstream processing.
Pair OCR with our data extraction API to identify key values, detect tables, and power intelligent workflows.
Recognize text across dozens of built-in languages, including accented scripts, symbols, and multilingual files.
Generate PDF/A outputs with full text layer for eDiscovery, records management, and accessibility.
HOW IT WORKS
Transform image-based PDFs into searchable, selectable content — ready for annotation, editing, or data extraction — with just three intuitive steps.
Upload a scanned PDF or image from your local device, or load it via API using Document Engine
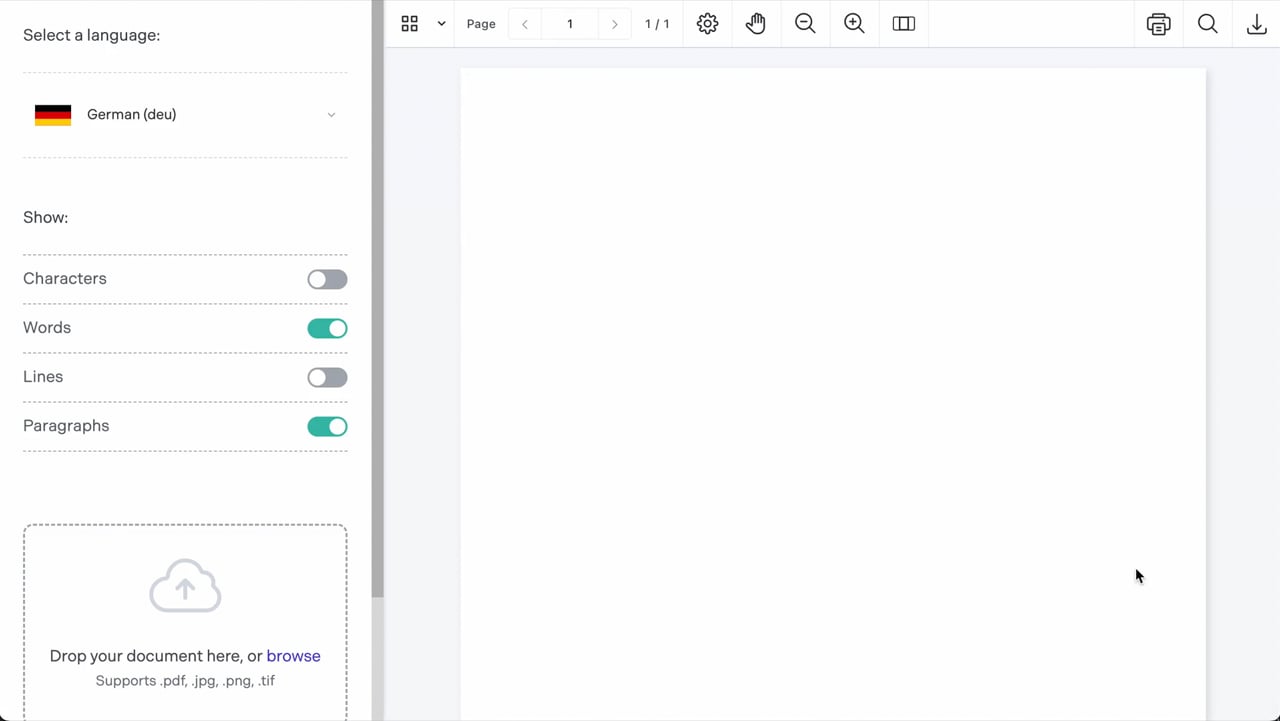
Choose your language(s), select specific pages, and configure content options — like whether to prioritize characters, words, or paragraphs.

Search, copy, annotate, extract, or edit the newly recognized text layer directly in your app. Use applyOperations (Web) or platform-specific OCR calls available in our mobile SDKs to process the file. Text becomes searchable and selectable.

KEY FEATURES
Unlock the text inside scanned PDFs and images — with export options for downstream workflows.

Make scanned documents searchable and highlightable.
OCR more than 30 built-in languages, including those with non-Latin character sets.
Embed a selectable text layer beneath the visual content — while preserving the original layout.
Pair OCR with our DWS-based data extraction API to identify tables and key-value pairs and trigger automated workflows.
Trigger OCR in production with a single operation using Web SDK and Document Engine.
Process documents offline using SDKs for iOS, Android, Mac Catalyst, React Native, and Flutter.
Process multilingual documents with ease.
.NET SDK
If you’re building in C# or need more advanced OCR capabilities, Nutrient .NET SDK offers a powerful alternative with expanded functionality:
Whether you’re building for web, mobile, or the backend, Nutrient gives you full flexibility — all with a consistent developer experience.
Use the web, mobile, and cross-platform SDKs to embed document capabilities directly into your app — fully client-side, no backend required
Use Document Engine for server-backed processing, data control, and deep infrastructure integration
WEB PLAYGROUND
REAL-WORLD IMPACT
Nutrient powers mission-critical document workflows for global enterprises — from compliance-heavy industries to modern SaaS teams.
Streamlined construction project collaboration with in-app markup and PDF tools — helping teams coordinate more effectively from jobsite to back office.
Used Nutrient to enable fast, focused board pack review with in-document annotations and threaded feedback — enhancing governance workflows across schools and nonprofits.
Empowers 34,000 pilots to view, annotate, and sign 90‑page flight releases on iPad using Nutrient iOS SDK, saving minutes — and money — on every flight.
FREE TRIAL
A PDF OCR SDK (optical character recognition software development kit) enables developers to integrate text recognition into apps, making scanned PDFs and image-based documents searchable and selectable. It works by detecting and converting text from rasterized content into a machine-readable layer that supports search, annotation, and editing.
Nutrient’s OCR functionality is available across Web (with Document Engine); .NET (C#); and mobile platforms, including iOS, Android, Mac Catalyst, React Native, and Flutter. This allows developers to deploy OCR across desktop, server, and mobile environments with a consistent API and architecture.
Yes. Nutrient OCR supports more than 30 languages (and 100+ in .NET), Unicode, and smart features like multi-language fallback and orientation detection — helping teams handle global content, mixed-language files, and skewed scans.
OCR transforms image-based documents into machine-readable text, making them accessible to screen readers, and enabling users to search, copy, and extract content. This is critical for digital accessibility, legal archiving, and productivity tools.
Pair OCR with Nutrient’s Data Extraction API to identify tables, key-value pairs, or form fields. Extracted data can then feed into downstream workflows like automation, analytics, or business logic.
Yes. On-device OCR is available in our mobile SDKs, allowing apps to recognize text without an internet connection. This is ideal for field work, remote teams, or environments with strict privacy requirements.
Use the Web SDK with Document Engine or the appropriate native SDK. Import your file, define the language and page range, and trigger the OCR operation. Nutrient provides robust guides, samples, and a free trial to get started.
SOLUTION OVERVIEW
Modern teams rely on OCR to unlock the value hidden in scanned PDFs and images — whether on the web, mobile, or desktop. From legal archives to field service forms, Nutrient’s OCR SDKs help teams move faster, work smarter, and stay compliant.
Looking for an OCR SDK that works where your users do? Nutrient makes it easy to add enterprise-grade OCR to your app — no complex setup or external tools required.




