Document Automation Server (DAS) OCR file handling
Table of contents
Nutrient Document Automation Server (DAS) contains three OCR engines: standard (using CuneiForm), extended (using Canon IRIS) and GdPicture. Each engine processes files differently, and this post will explore how they handle various document types and where each one works best.
Test the standard, extended, and GdPicture OCR engines in your own workflow and see which is the best fit.
Test setup: Putting the OCR engines to work
To show how the three OCR engines handle different documents, we created a document that contains the following types of pages in it:
- One page born-digital(opens in a new tab) — just text, e.g. exported from Word
- One page born-digital — text, but also with a screenshot image containing legible text
- One page born-digital — text with annotations
- One page image PDF — with no selectable text
- One page image PDF — with Bates numbers or similar selectable text
- One page image PDF — with text-carrying annotations, such as a text box or note
- One page image PDF — previously OCR’ed, not by us
Having these different page formats in a single document gives us the widest view of how all three engines handle, or could potentially handle, files that fall into the types above.
The document was then processed using standard OCR, extended OCR, and GdPicture OCR.
Standard OCR (CuneiForm engine)
The standard OCR engine, which is based on CuneiForm, is recommended mainly when a customer would like to process a document that exceeds the dimensions supported by the extended OCR engine.
In most cases, the extended OCR engine provides more accurate OCR results across a wider range of languages and original document quality.
In our test document, each page was OCR’d correctly; however, as can be seen below, a minor glitch occurred.

In the image above, using the key combination Control-A resulted in it being highlighted. This behavior is mostly expected, but the large blue bar shouldn’t be present. Furthermore, a line of text hasn’t been OCR’d. When checking the output documents from the extended engine and the GdPicture engine, the large bar wasn’t present.
Extended OCR (Canon IRIS)
The extended OCR engine, which is based on the Canon IRIS engine, is the go-to OCR solution for Document Automation Server. It provides the most reliable OCR and has a few more options like multi-language support, PDF output versioning, and PDF/A validation.
To show how much more reliable the Canon IRIS engine is, the image below shows the same snippet as in the standard OCR example.

As can be seen above, the highlighted text is more accurate to the words themselves, and the blue bar that was present with the standard engine isn’t present in this document.
One of the main issues we’ve seen with the extended OCR engine is that, very rarely, a customer will try to process a document that exceeds the dimensions the engine can handle, which will then cause an error that looks similar to the following:
"Loading D:\Aquaforest\Autobahn DX\work\8194\work1\source\589521.pdf (1) pages…Processing page 1The number of pixels in the supplied image size exceeds the maximum allowed value.Extended OCR has the following image limits:Max Height = 32,768 pixelsMax Width = 32,768 pixelsMax Size = 75,000,000 pixelsCould not process page 1."The error message above shows the maximum dimensions and pixel count. This allows the user to verify whether the file’s pixel count or dimensions exceed the extended OCR processing thresholds.
In this instance, we’d ask the user to try standard OCR, as it isn’t limited by the pixel count/dimensions of a document, and it’ll be able to OCR this type of document.
An example we’ve previously seen is when our extended OCR engine is trying to process a CAD file. As these file types are often high resolution, they exceed the capabilities of the extended OCR engine.
It’s important to note that this is a very rare occurrence, as typically, standard A4-sized pages are processed using our software.
GdPicture engine
GdPicture has been used by customers mainly due to its processing speed and versatility with supported input files. Furthermore, it allows for multithreaded document processing. As an example, a core will process a document, and a thread will process a page within that document. This means that if four cores are assigned to a job, four documents will be processed at once. Meanwhile, if the thread count is set to two, two pages in those four documents will be processed at the same time.
Being able to change the amount of CPU cores and threads being used in a job means that GdPicture can be tailored to the specific types of files being processed.
For example, consider a system with 10 cores and 20 threads. If you need to process 10 very large documents (each more than 100 pages), you could set the core count to 2 and the thread count to 9. This configuration processes 2 documents at the same time, with 9 pages per document being handled in parallel — a total of 18 threads — while leaving 2 threads free for system stability. This setup maximizes speed for large files.
On the other hand, if you’re dealing with many small files (say 50 single-page documents), you could set the core count to 9 and the thread count to 1. In this case, 9 documents are processed at the same time, one page each, which improves throughput for lots of smaller jobs.
| Scenario | Cores | Threads | Documents processed at once | Pages per document | Total threads used | Notes |
|---|---|---|---|---|---|---|
| Large documents (100+ pages) | 2 | 9 | 2 | 9 | 18 | Leaves two threads free for stability. |
| Many small documents (1 page) | 9 | 1 | 9 | 1 | 9 | Optimized for throughput on small jobs. |
Furthermore, GdPicture allows already OCR’d pages to be skipped. In the test document, this can be seen in the output logs in the screenshot below.
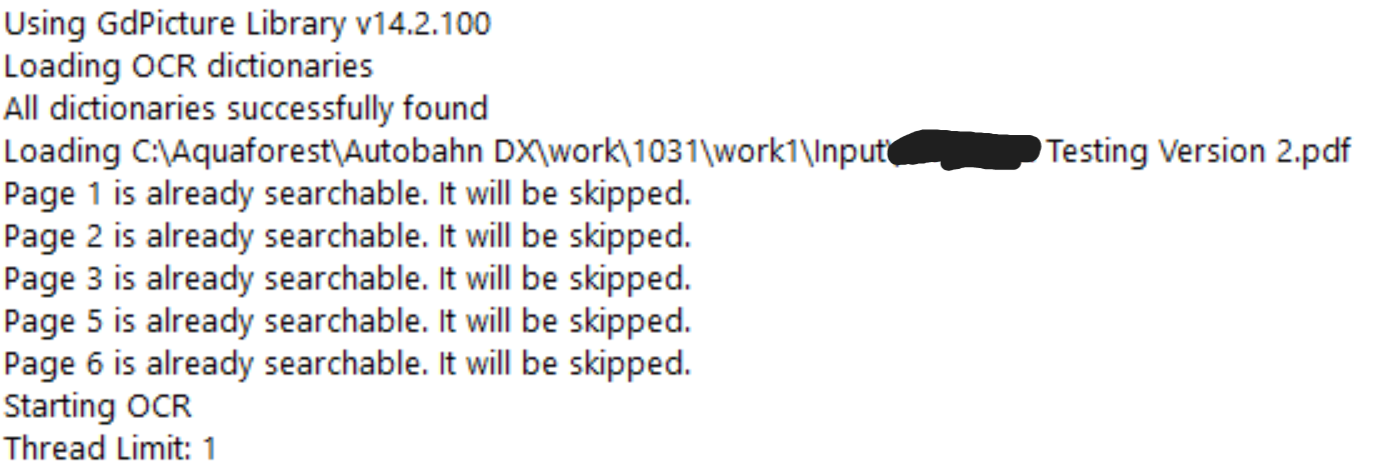
Out of the seven pages, pages four and seven were OCR’d. This is because the GdPicture engine detected that those two pages weren’t fully searchable.
The GdPicture engine has known limitations, and one of them is the inability to process handwritten text. Recognition of handwriting isn’t supported, regardless of legibility. This is the same for most OCR engines. As a general rule, our software is designed to process printed or typed text; if a human can read it easily and it’s born-digital, our OCR engines should be able to process it.
Conclusion
To conclude, each of our three OCR engines have their strengths and weaknesses, but the general rule of thumb for which engine should be used is as follows:
- Standard OCR engine — Used for larger files that exceed the dimensions of the extended OCR engine.
- Extended OCR engine — The engine to use by default, allowing a happy medium between OCR quality and system resources used,
- GdPicture OCR engine — Used in “catch-all” jobs that can have a wide range of file types thrown at it, and for when a fine balance between processing speed and resource usage needs to be found to ensure maximum throughput of data processed.
By understanding how each engine handles different document types, you can optimize performance, save processing time, and get more consistent results.
Ready to see which OCR engine is right for your workflow? Learn more about Document Automation Server, or get in touch with our team to explore how Nutrient can fit your document processing needs.