How key-value pair extraction works
Nutrient .NET SDK’s (formerly GdPicture.NET) key-value pair (KVP) extraction engine enables you to recognize related data items in a document and export them to an external destination like a spreadsheet. Nutrient .NET SDK can automatically perform all the steps of the following example workflow:
- Scan a physical copy of a document or load a document file.
- Preprocess the document to correct common problems such as noise, poor character quality, and skewed pages.
- Recognize the text with optical character recognition (OCR) technology.
- Recognize the document type, such as a bank statement, and adapt the extraction approach accordingly.
- Recognize key data items, such as IBANs and addresses.
- Export the data to an external destination like a spreadsheet.
- Redact sensitive information, such as credit card numbers, from the scanned document.
This guide explains KVP extraction in detail (steps 4 and 5 in the example workflow above). The steps above are illustrative and optional, and your workflow might be significantly different. For example, instead of scanning and preprocessing a physical document, you can use a digitally generated document. Nutrient .NET SDK supports more than 100 file types.
For more information on KVP extraction, watch the video below.
Key-value pair extraction
Key-value pairs are two related data items: a key and a value. Depending on the type of document, the key-value pairs are different. For example, key-value pairs on invoices can be the following:
| Key | Value |
|---|---|
| Invoice Number | No 00162 |
| Billing Date | 20/09/2022 |
| Total | 1,165.10€ |
Key-value pair fields on government forms can be the following:
| Key | Value |
|---|---|
| Company Name | Nutrient GmbH |
| Registration Number | FN 548939p |
| Date of Incorporation | 04/10/2013 |
It’s convenient to get key-value pairs from structured documents like Excel files because the values are all named. However, 90 percent of all documents have unstructured data. For these documents, you need a KVP extraction tool to retrieve the information. Intelligent document processing (IDP) extracts data from unstructured and semi-structured documents using OCR and artificial intelligence (AI) technologies.
By automatically recognizing the document type, Nutrient .NET SDK adapts to the context and determines the extraction approach that makes the best use of available resources. Nutrient .NET SDK recognizes the document type based on adaptive layout understanding and natural language processing (NLP) technologies. This hybrid approach includes heuristics, mathematics, and machine learning (ML) capabilities that address the usual weaknesses of traditional OCR and pure ML engines.
How to use key-value pair extraction
This example retrieves key-value pairs, such as invoice number and billing date, from the scanned invoice below.
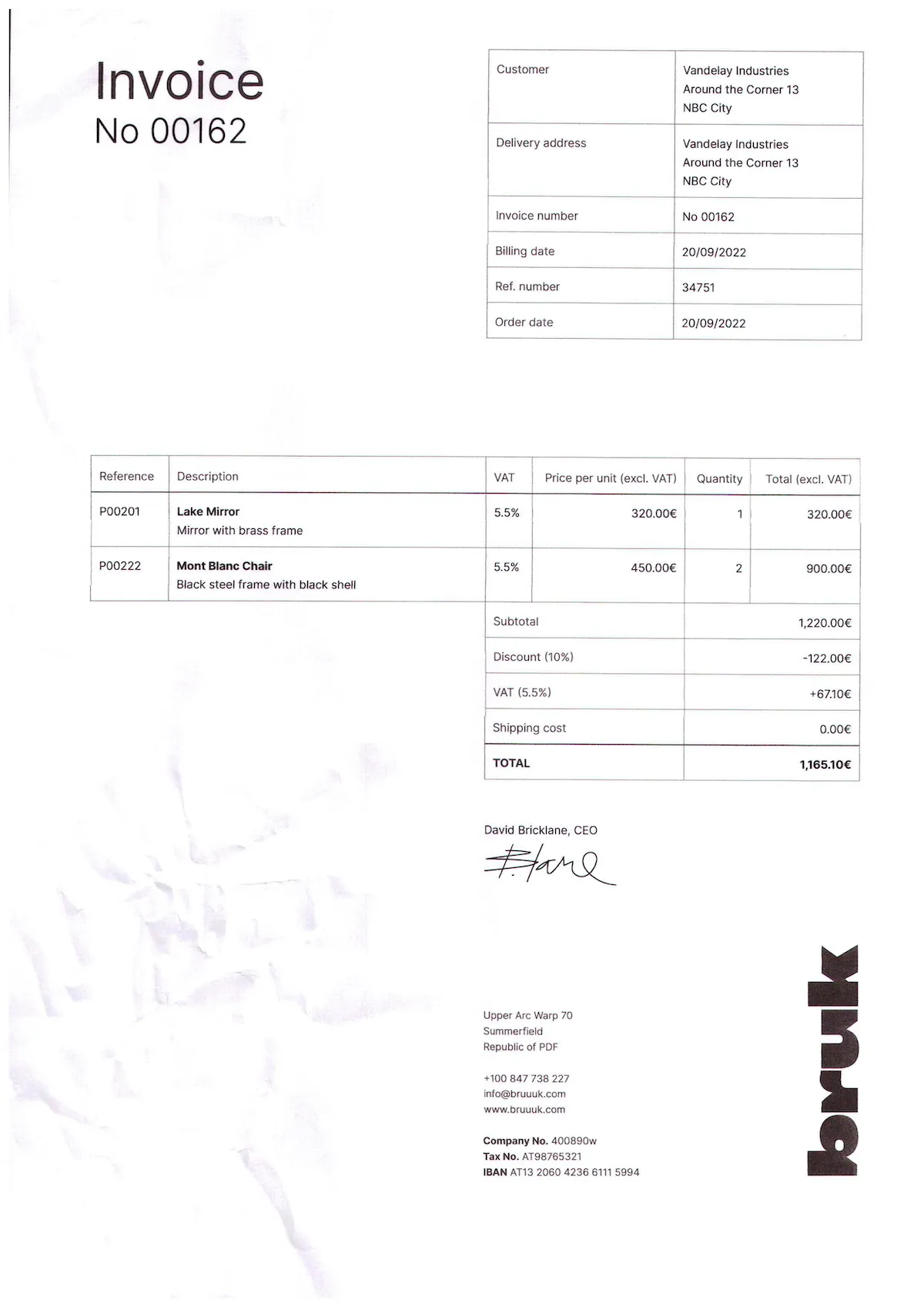
To extract data items from the invoice, use the code example below:
=
using GdPictureOCR gdpictureOCR = new GdPictureOCR();using GdPictureImaging gdpictureImaging = new GdPictureImaging();// Load the source document.int imageId = gdpictureImaging.CreateGdPictureImageFromFile(@"C:\temp\source.png");// Configure the OCR process.gdpictureOCR.ResourceFolder = @"C:\GdPicture.NET 14\Redist\OCR";gdpictureOCR.AddLanguage(OCRLanguage.English);gdpictureOCR.SetImage(imageId);// Run the OCR process.string ocrResultId = gdpictureOCR.RunOCR();string keyValuePairsData = "";for (int pairIndex = 0; pairIndex < gdpictureOCR.GetKeyValuePairCount(ocrResultId); pairIndex++){ keyValuePairsData += $"| Key: {gdpictureOCR.GetKeyValuePairKeyString(ocrResultId, pairIndex)} | " + $"Value: {gdpictureOCR.GetKeyValuePairValueString(ocrResultId, pairIndex)} | " + $"Document Type: {gdpictureOCR.GetKeyValuePairDataType(ocrResultId, pairIndex).ToString()} | " + $"Confidence Level: {Math.Round(gdpictureOCR.GetKeyValuePairConfidence(ocrResultId, pairIndex), 1).ToString()}% |\n";}// Write the output to the console.Console.WriteLine(keyValuePairsData);// Release unnecessary resources.gdpictureImaging.ReleaseGdPictureImage(imageId);gdpictureOCR.ReleaseOCRResults();Using gdpictureOCR As GdPictureOCR = New GdPictureOCR()Using gdpictureImaging As GdPictureImaging = New GdPictureImaging() ' Load the source document. Dim imageId As Integer = gdpictureImaging.CreateGdPictureImageFromFile("C:\temp\source.png") ' Configure the OCR process. gdpictureOCR.ResourceFolder = "C:\GdPicture.NET 14\Redist\OCR" gdpictureOCR.AddLanguage(OCRLanguage.English) gdpictureOCR.SetImage(imageId) ' Run the OCR process. Dim ocrResultId As String = gdpictureOCR.RunOCR() Dim keyValuePairsData = ""
For pairIndex As Integer = 0 To gdpictureOCR.GetKeyValuePairCount(ocrResultId) - 1 keyValuePairsData += $"| Key: {gdpictureOCR.GetKeyValuePairKeyString(ocrResultId, pairIndex)} | Value: {gdpictureOCR.GetKeyValuePairValueString(ocrResultId, pairIndex)} | Document Type: {gdpictureOCR.GetKeyValuePairDataType(ocrResultId, pairIndex).ToString()} | Confidence Level: {Math.Round(gdpictureOCR.GetKeyValuePairConfidence(CStr(ocrResultId), CInt(pairIndex)), CInt(1)).ToString()}% |" & vbLf Next ' Write the output to the console. Console.WriteLine(keyValuePairsData) ' Release unnecessary resources. gdpictureImaging.ReleaseGdPictureImage(imageId) gdpictureOCR.ReleaseOCRResults()End UsingEnd Using=
Format the output to obtain the following table:
| Key | Value | Document Type | Confidence Level |
|---|---|---|---|
| Billing date | 20/09/2022 | DateTime | 100% |
| Order date | 20/09/2022 | DateTime | 100% |
| Republic of PDF | +100 847 738 227 | PhoneNumber | 77.2% |
| IBAN | AT13 2060 4236 6111 5994 | IBAN | 100% |
| Customer | Vandelay Industries Around the Corner 13 NBC City | String | 69.8% |
| Delivery address | Vandelay Industries Around the Corner 13 NBC City | String | 69.9% |
| Invoice number | No 00162 | String | 70.9% |
| Ref. number | 34751 | Number | 92.9% |
| No | 00162 | Number | 100% |
| Reference | P00201 | UID | 100% |
| Quantity Total (excl. VAT) | 320.00€ | Currency | 59% |
| Subtotal | 1,220.00€ | Currency | 100% |
| Discount (10%) | -122.00€ | Currency | 90.6% |
| VAT (5.5%) | +6710€ | Currency | 66.9% |
| Shipping cost | 0.00€ | Currency | 75% |
| TOTAL | 1,165.10€ | Currency | 100% |
| Description | Lake Mirror | String | 99.6% |
| VAT | 5.5% | Percentage | 66.6% |
| Price per unit (excl. VAT) | 320.00€ | Currency | 80% |
| Tax No. | AT98765321 | UID | 73.8% |
| # | infe@bruuuk.com | EmailAddress | 65.6% |
| # | www.bruuuk.com | URL | 65.6% |
This table also contains information about the data type and the confidence level for each key-value pair:
- The data type describes the nature of the content. In this example, the engine recognizes the value
infe@bruuuk.comas an email and the value+100 847 738 227as a phone number. - The confidence level describes how confident the KVP engine is in the accuracy of the data extraction.
In this example, the KVP engine automatically detected all key-value pairs in the document with minimal code and without any preconfiguration. The engine supports more than 100 formats and languages, and it has no dependencies to external models, resources, and databases.
Next steps
- Data model
- Confidence score
- Extract data from bank statements
- Extract data from tables
- Extract data from invoices