





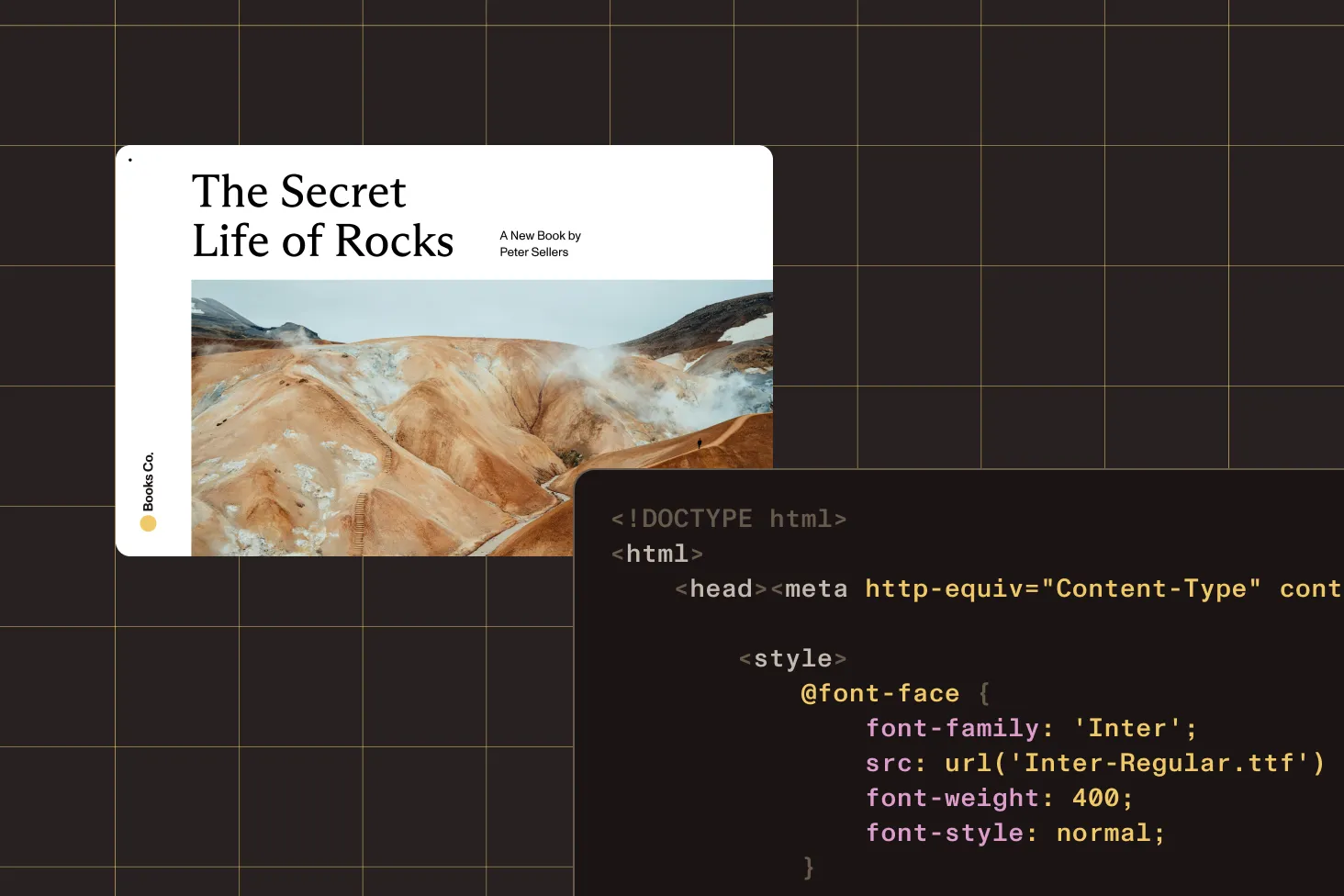
Teaching LLMs to read PDFs: Convert PDF to HTML and Markdown with Claude Code and Nutrient DWS MCP Server
Convert PDF to Markdown and HTML for LLMs and AI workflows using Claude Code and the Nutrient DWS MCP Server — restoring the structure that the PDF format strips away.