




Extract text from PDFs with Nutrient Document Web Services API on Zapier
Table of contents

What is Zapier?
Zapier(opens in a new tab) is an automation platform that connects your favorite apps and services with no code required. You can build “Zaps” to automate repetitive tasks by setting up triggers and actions between apps like Google Drive, Slack, Gmail, and more.
In this tutorial, you’ll learn how to use Zapier to automatically extract plain and structured text from PDF documents using Nutrient DWS Processor API.
What is Nutrient DWS Processor API?
Nutrient Document Web Services API is a powerful platform for document automation. With your free account(opens in a new tab), you get 200 credits, which you can use to perform various document operations. Each tool (e.g. conversion, signing, flattening) consumes a different amount of credits depending on complexity.
Nutrient offers more than 30 tools with the ability to:
- Convert images and documents to PDF
- Merge, split, or reorder pages
- Add digital signatures, watermarks, or annotations
- Run OCR, redact, flatten, and more
What you’ll need
- A Zapier(opens in a new tab) account (a pro plan is necessary for multistep Zaps)
- A Google Drive account
- A PDF file uploaded to Google Drive
- A Nutrient DWS Processor API key — sign up here(opens in a new tab)
Step 1 — Trigger a new file in a Google Drive folder
- Select Google Drive as the trigger app.

- Choose the New File in Folder trigger event.
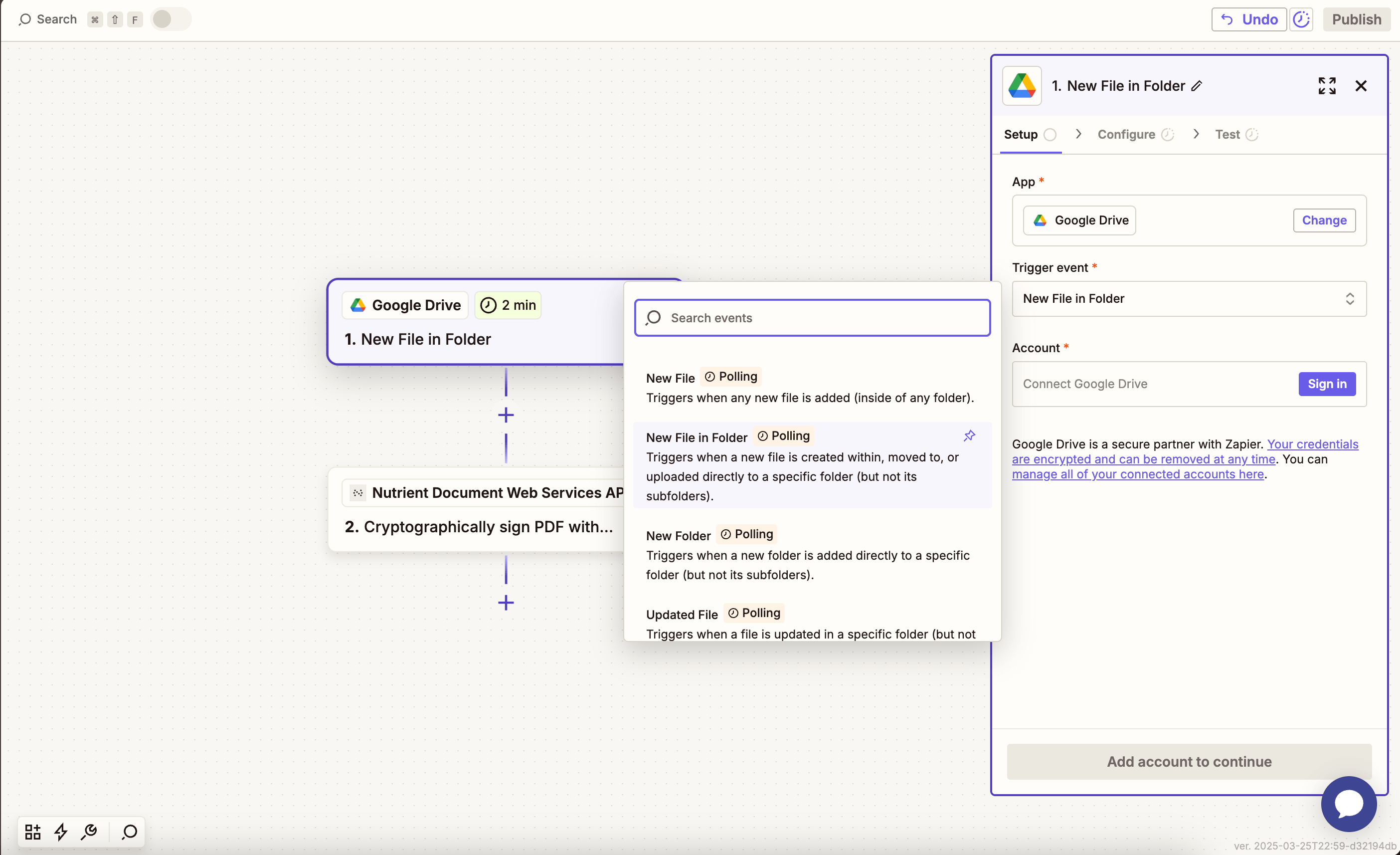
- Connect your Google Drive account.
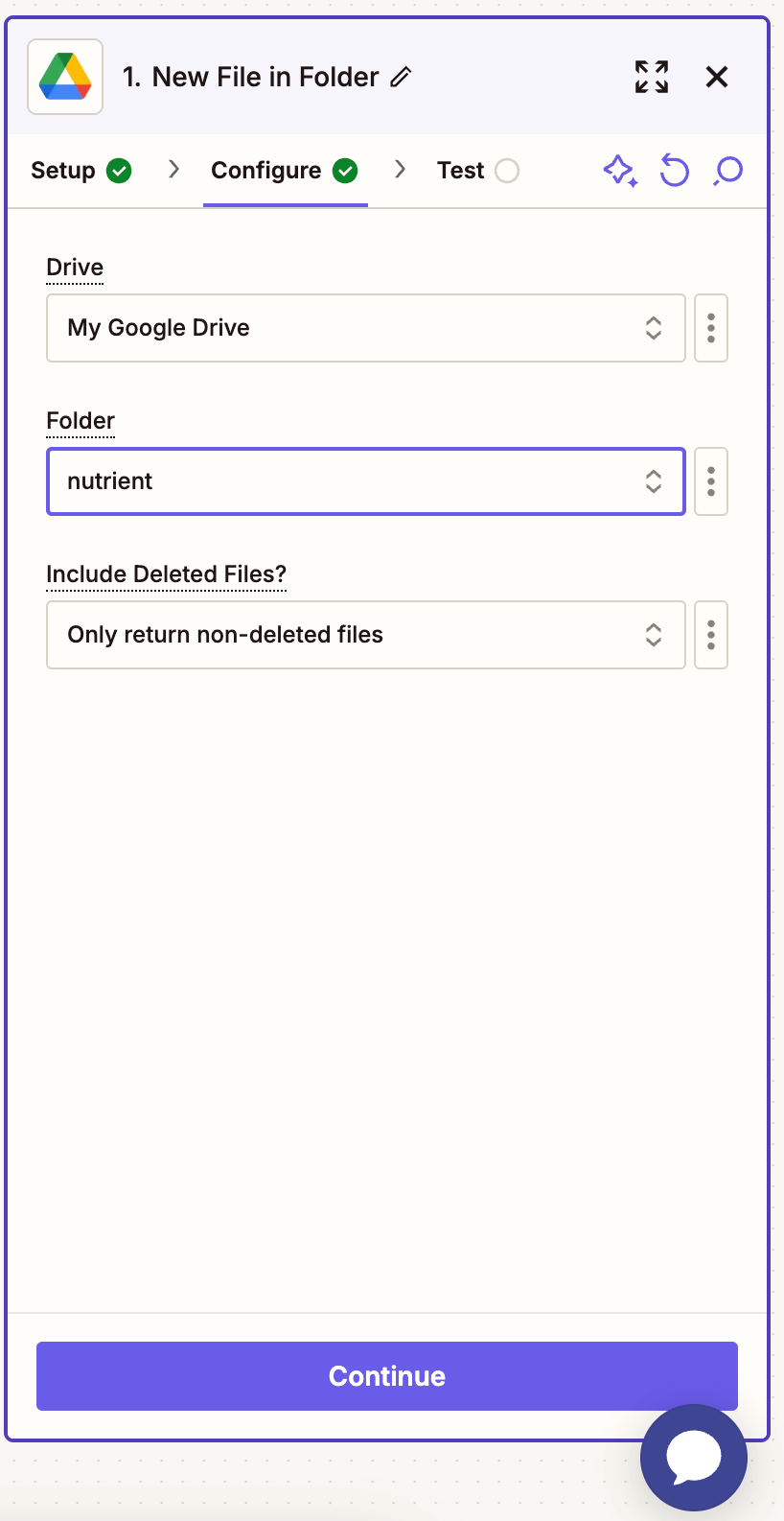
- Set up the trigger:
- In the Drive field, select your Google Drive.
- In the Folder field, select or create a folder (e.g.
pdf-to-text).
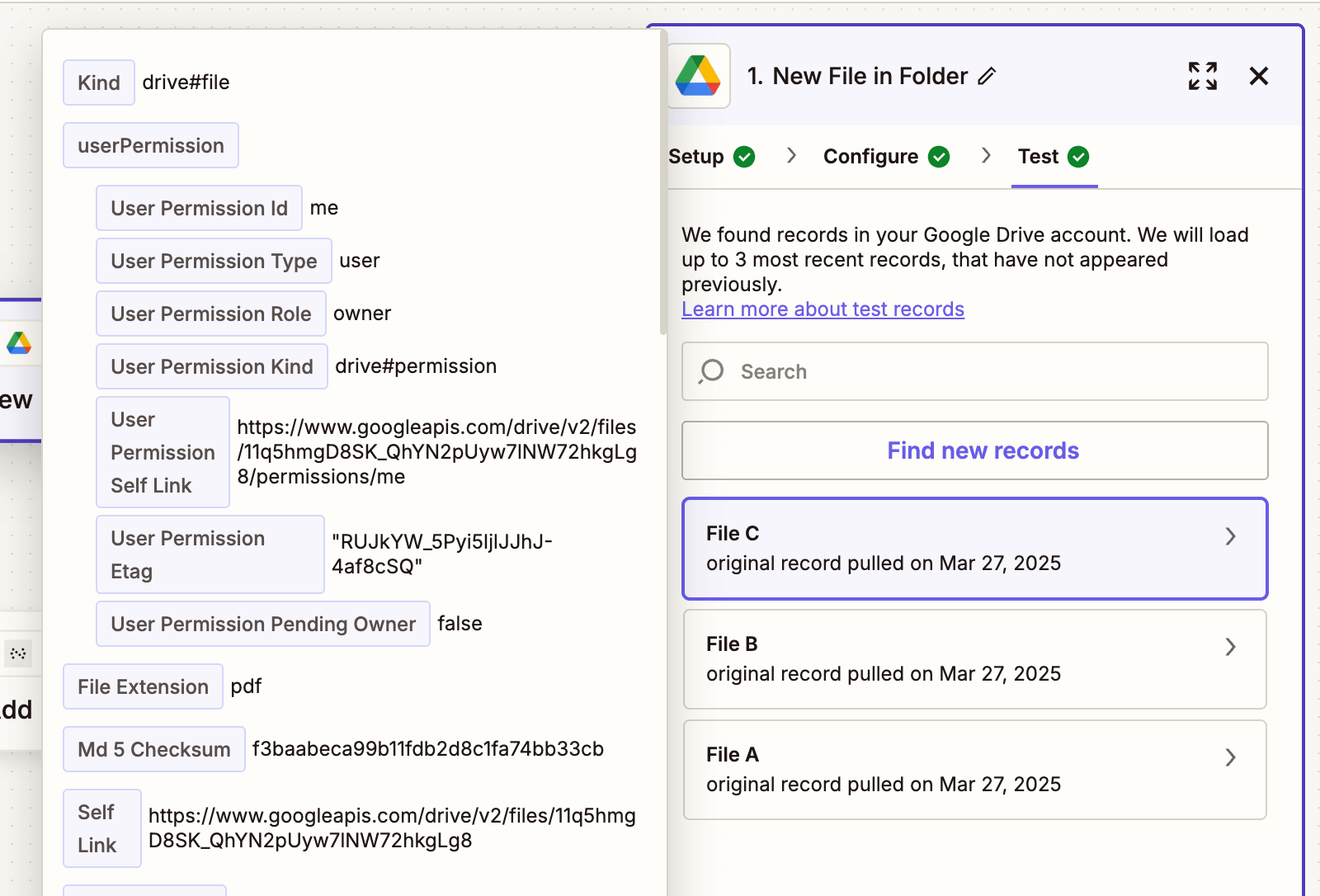
- Test this step with a sample PDF file.
Step 2 — Extract text from PDF action using Nutrient DWS Processor API
- Select Nutrient Document Web Services API as your action app.
- Choose the Extract Text From PDF action.
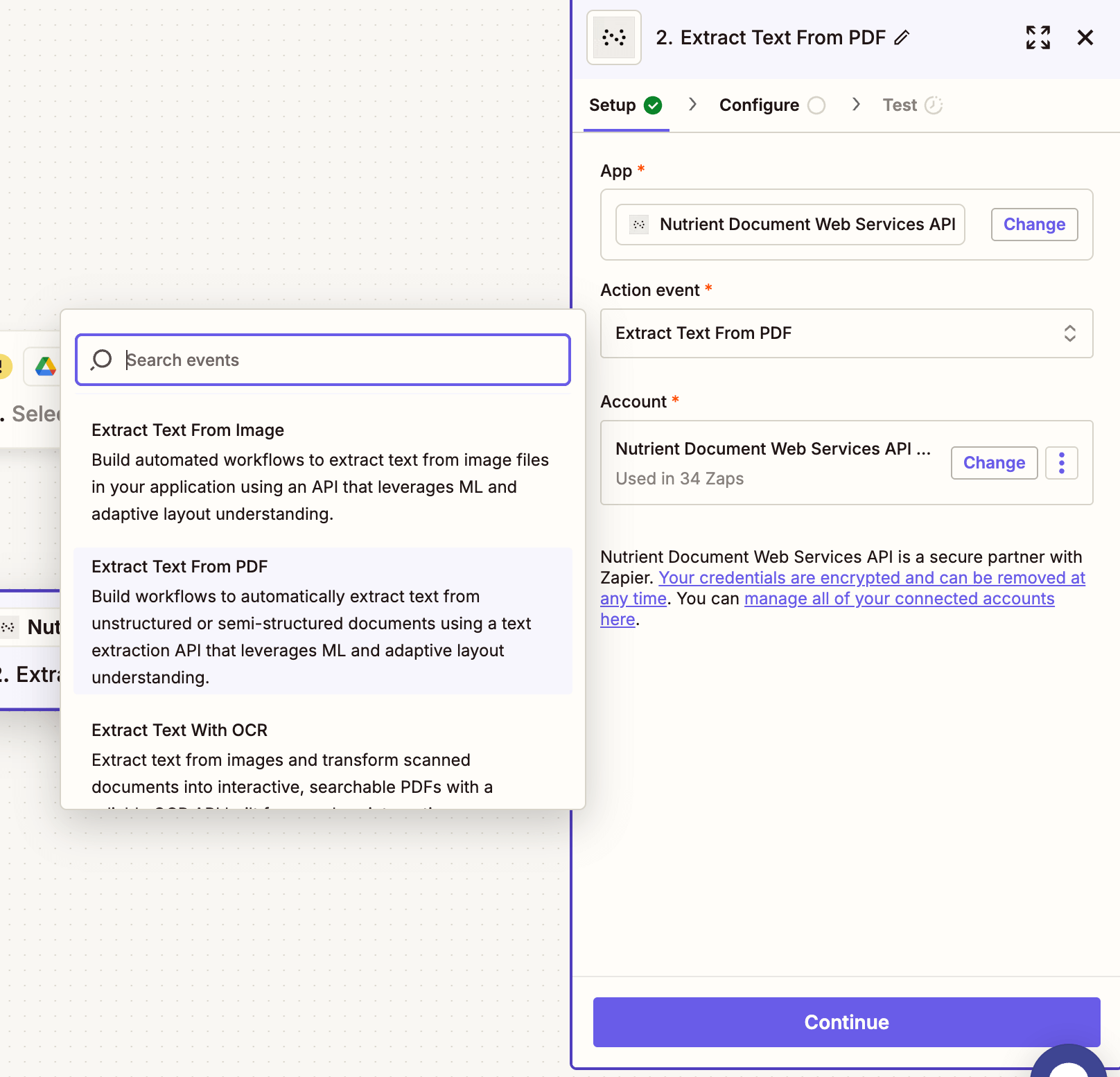
- Connect your Nutrient DWS Processor API account using your API key.
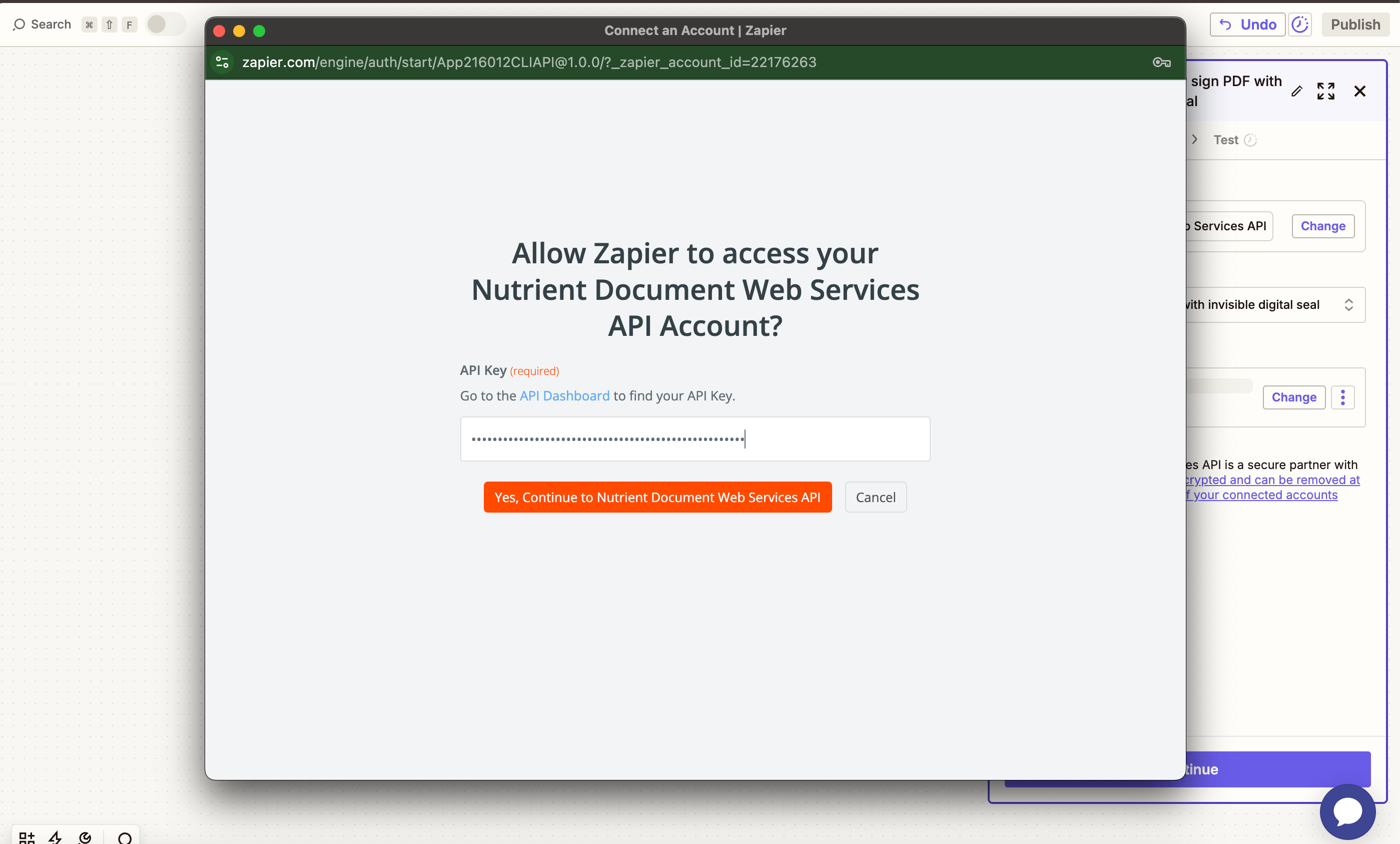
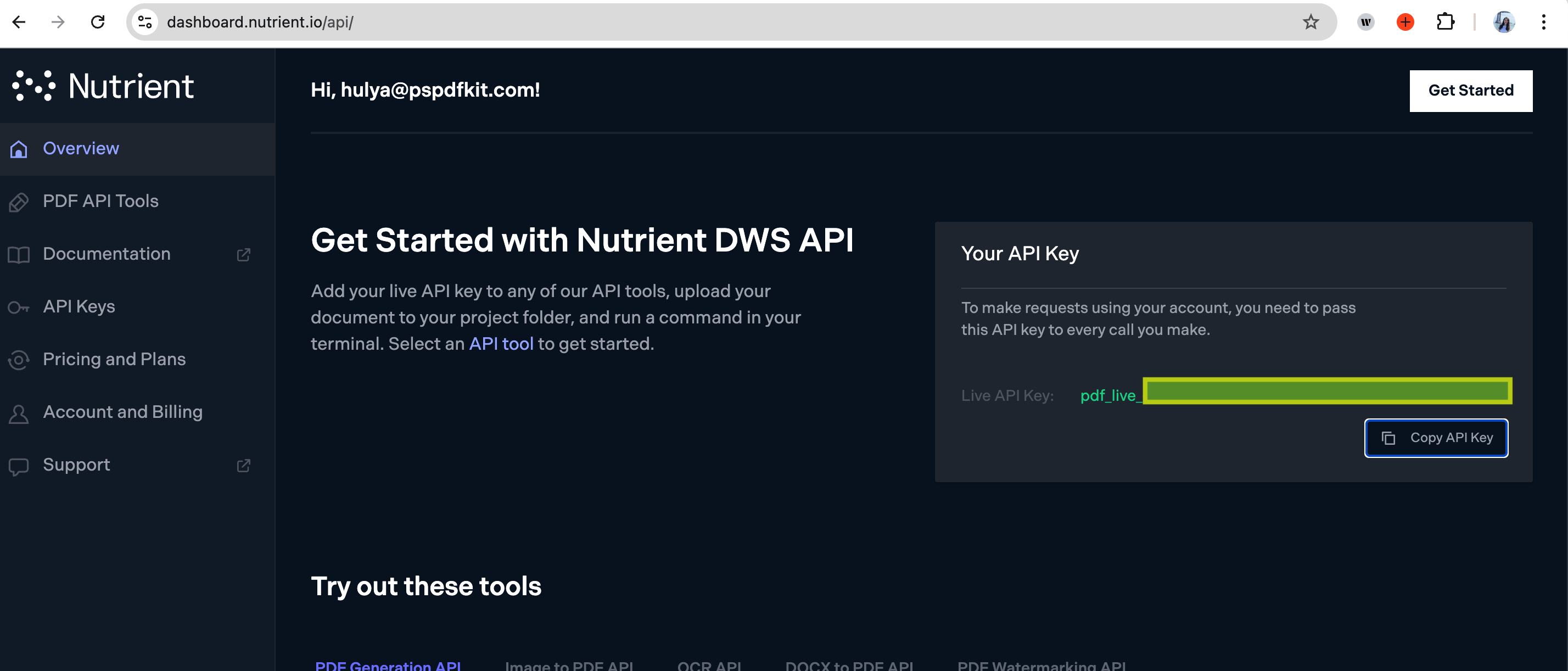
You can find your key in the Nutrient dashboard(opens in a new tab).
- Configure the action:
- PDF File URL — Use the output from step 1.
- Output File Name — Optional — e.g.
invoice-text.txt.
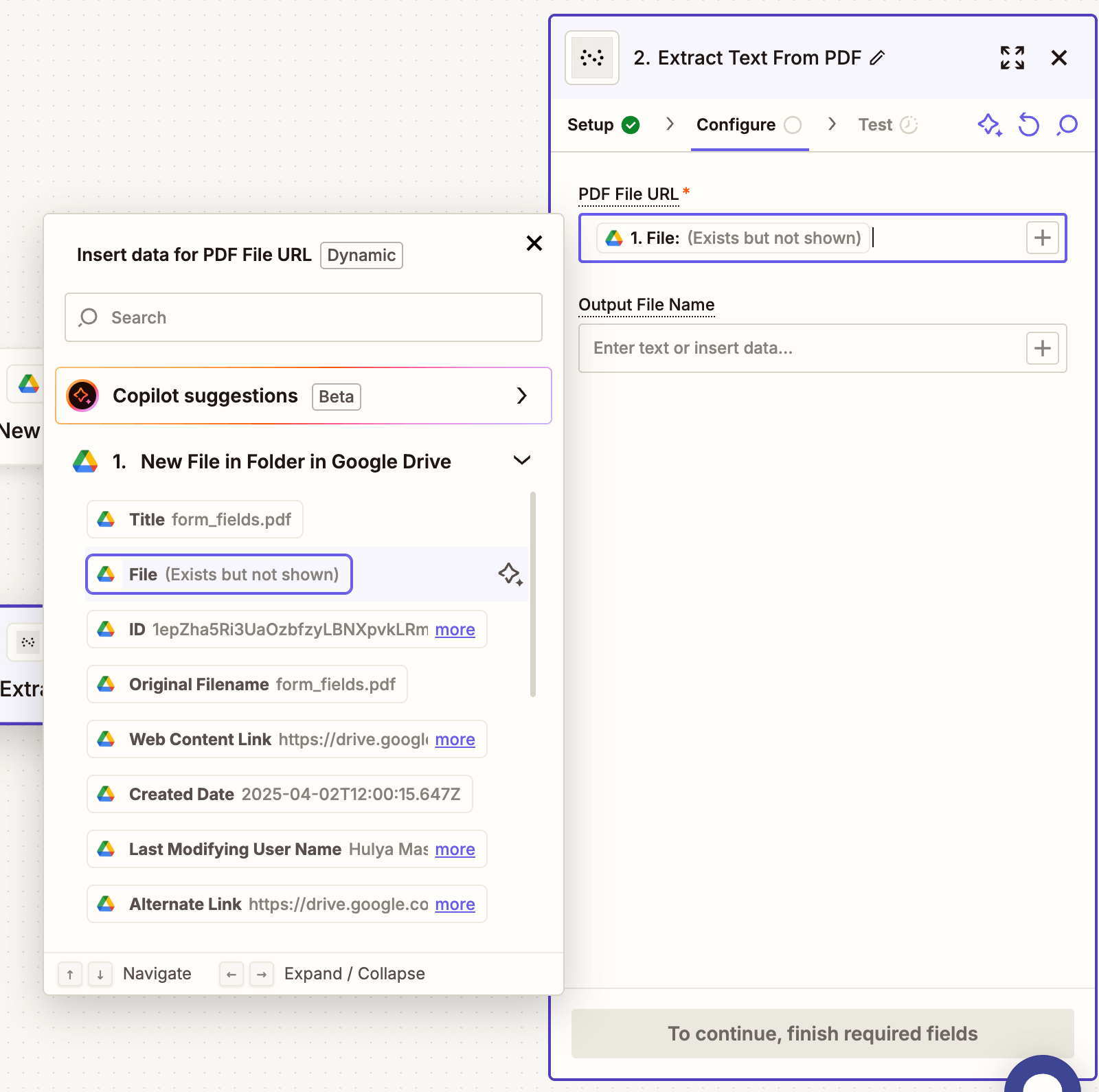
Make sure the file is publicly accessible or uploaded through a supported trigger like Google Drive.
- Run a test to ensure the extracted text is returned in structured JSON format.
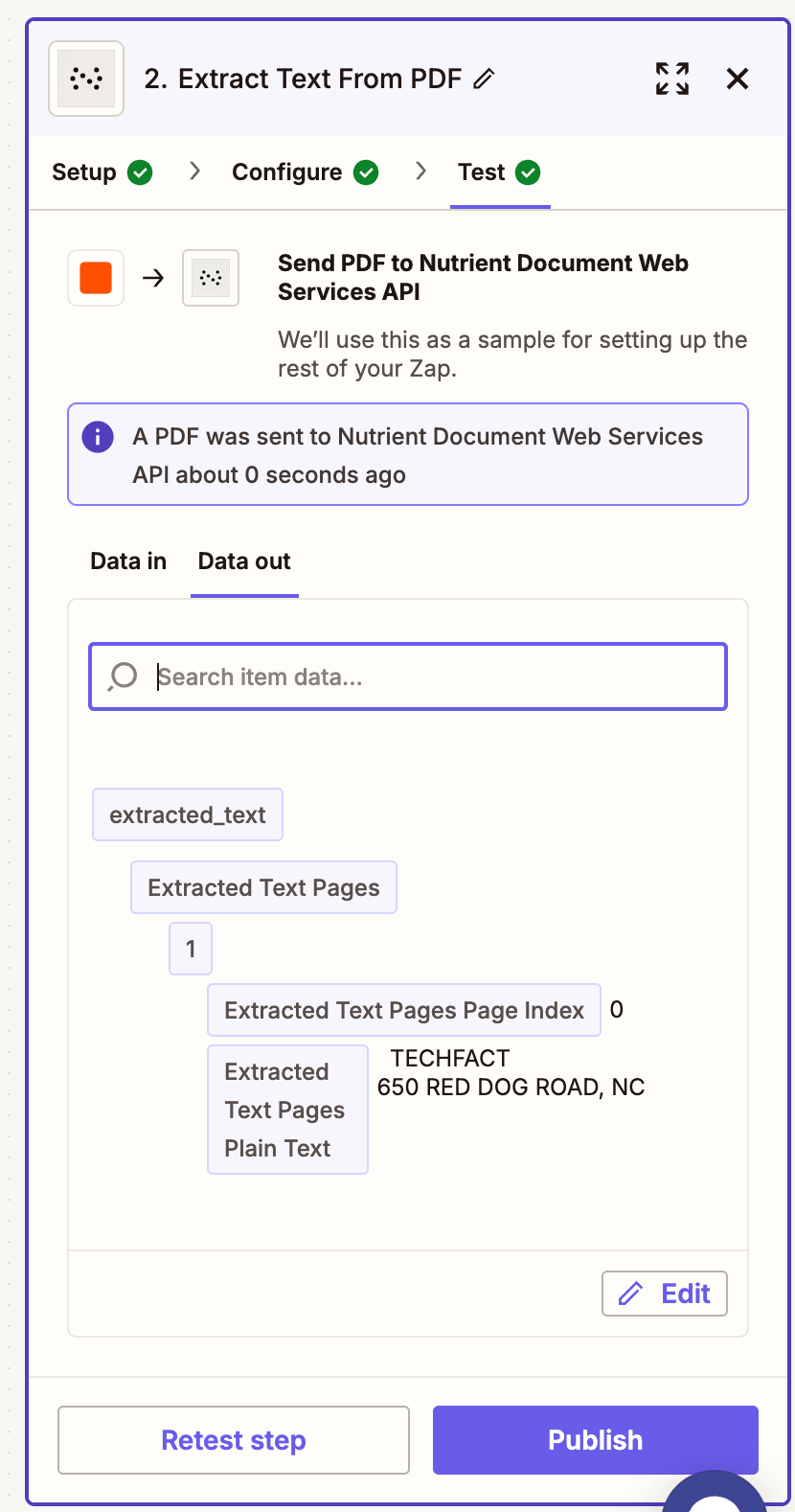
Step 3 — Upload the extracted data to Google Drive (optional)
- Now, add another step by selecting Google Drive as the app and Upload File as the action event. Connect your Google Drive account if needed.
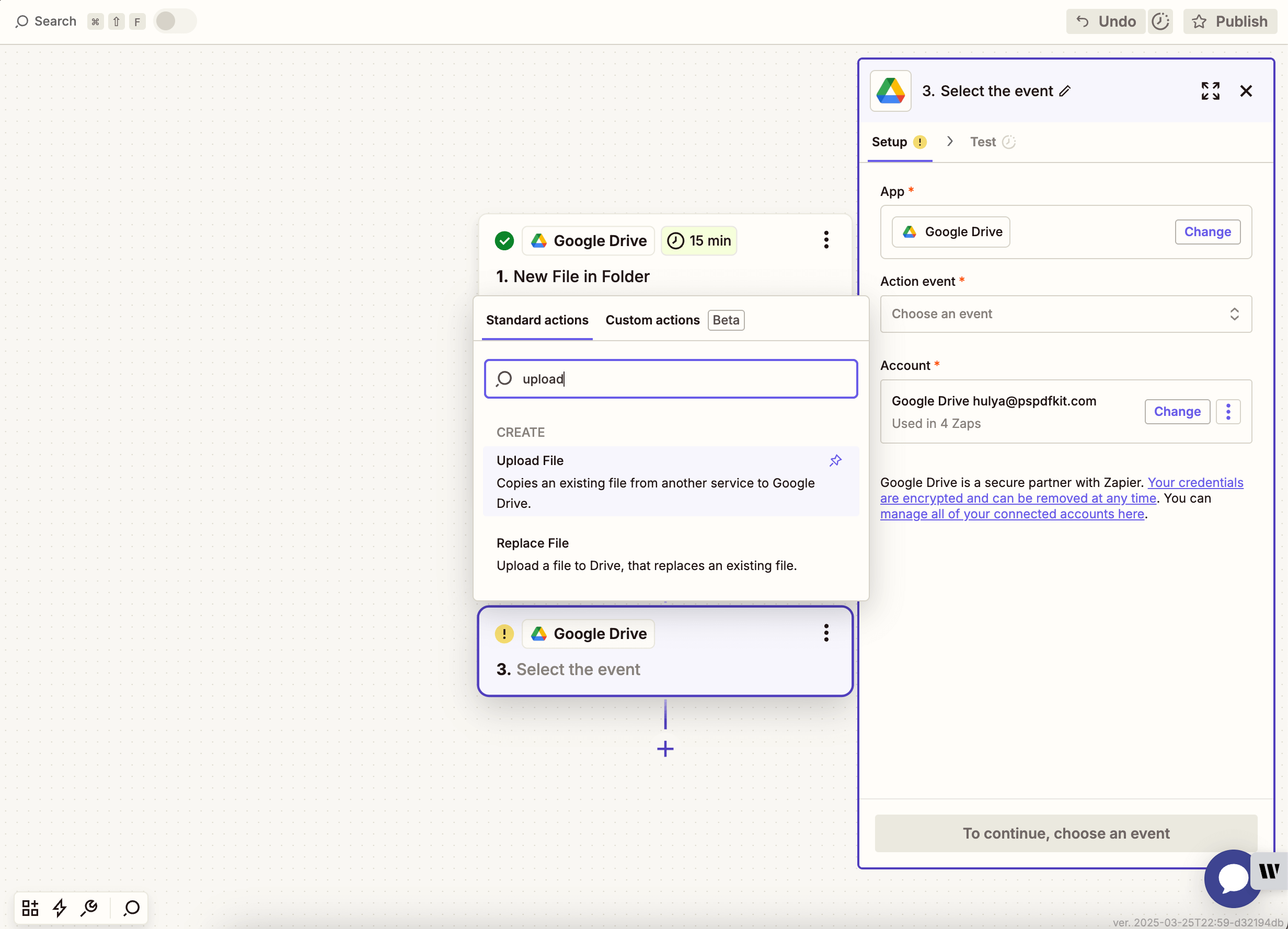
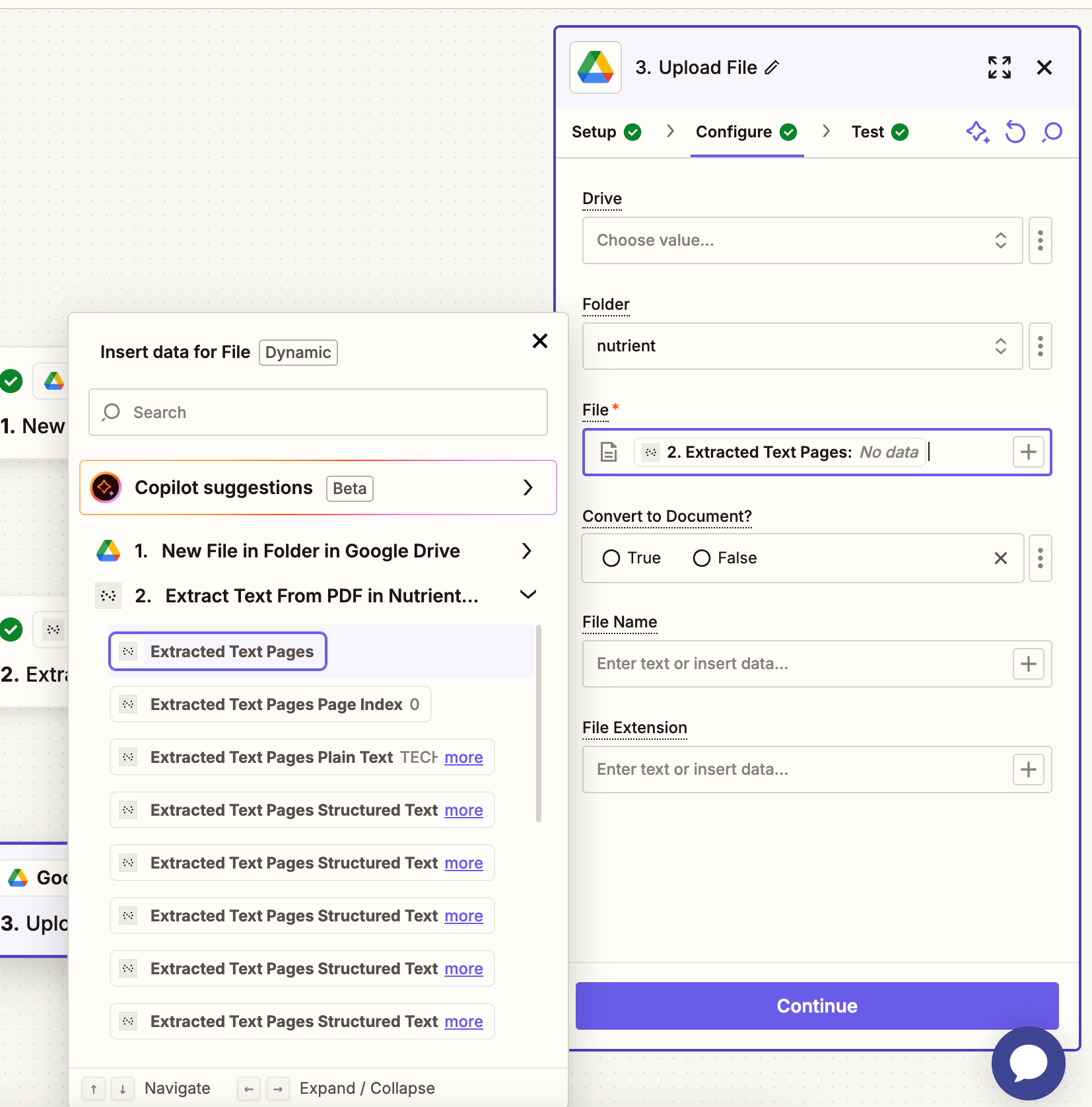
- Choose your drive and output folder.
- In the File field, map the extracted JSON file or raw content.
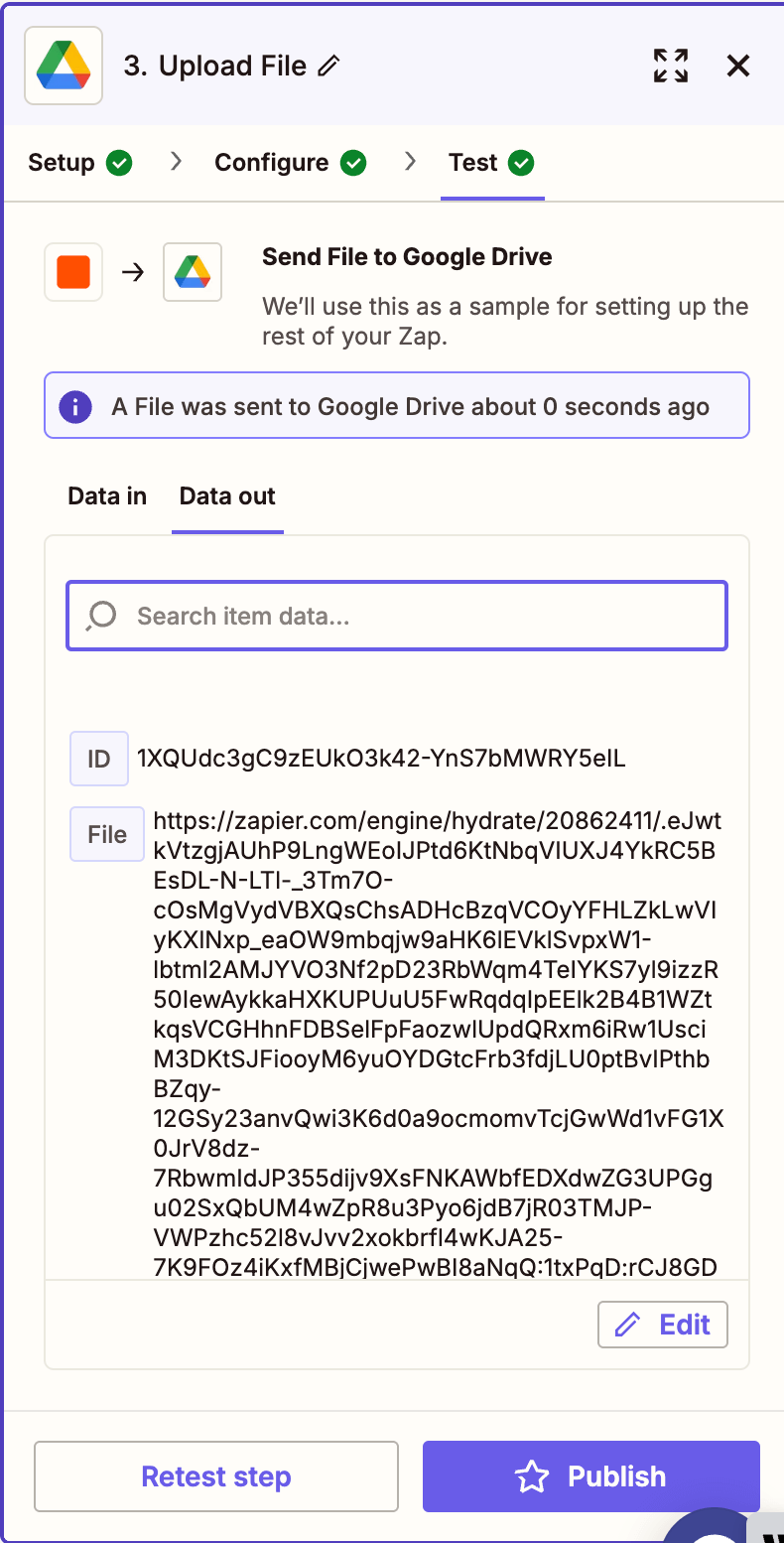
- Run a test to confirm the extracted file uploads properly.
Conclusion
With this Zap, you’ve automated the process of extracting plain and structured text from PDFs using Nutrient DWS Processor API(opens in a new tab). This workflow is ideal for indexing content, digitizing business records, or feeding content into CRMs and data pipelines.
You can expand this flow with steps for table extraction, OCR scanning, or automatic uploading to Notion(opens in a new tab).


