




Automate your zonal OCR PDF workflows
Extract structured data from PDFs using intuitive, low-code zonal OCR tools. No manual retyping, no code — just precision, efficiency, and scale.
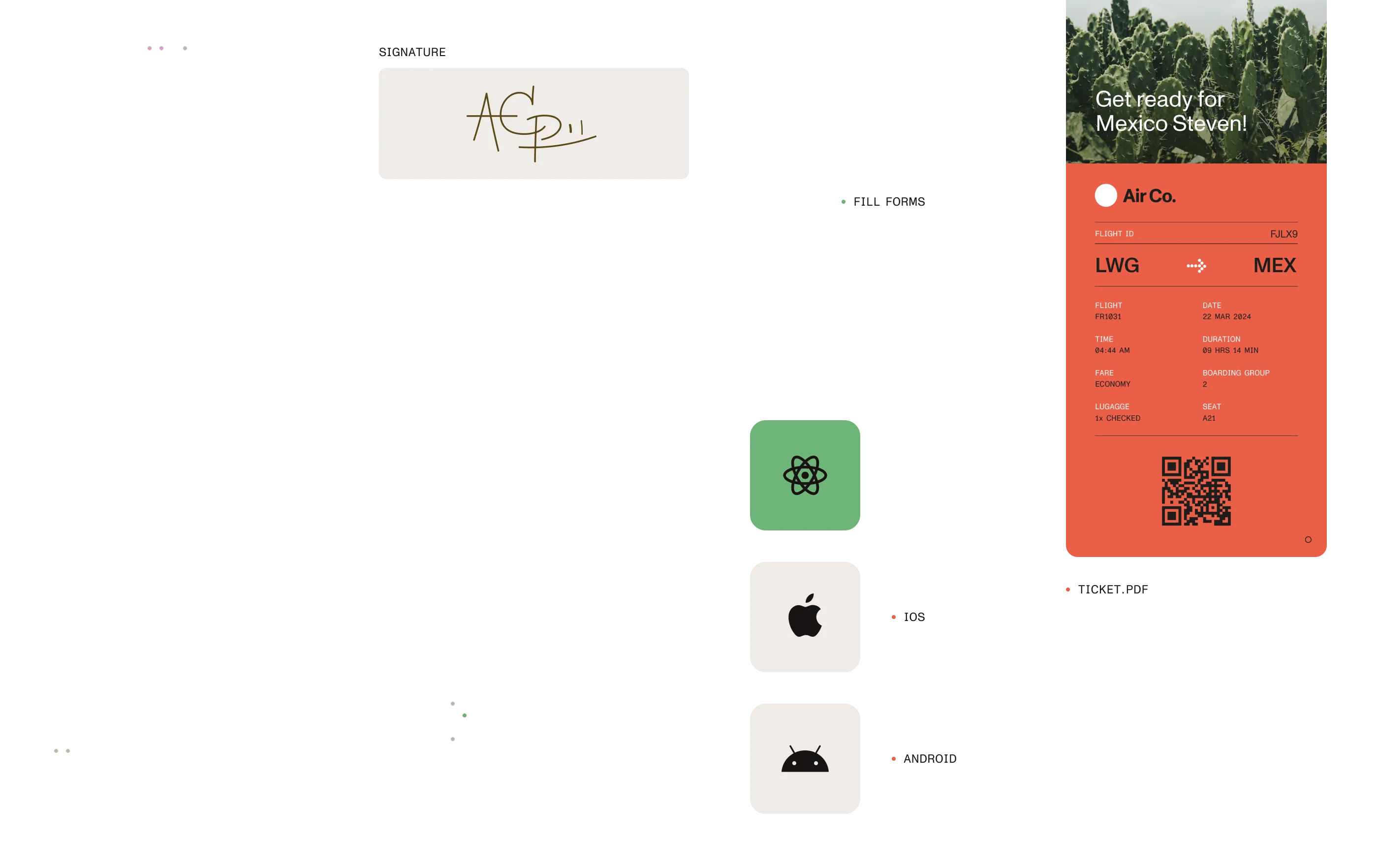

How We help
How we help
Extract key data from PDFs
Define zones on PDFs to capture names, dates, totals, and other critical data fields—export as structured results without manual data entry.
Automate invoice and form processing
Pull invoice numbers, client data, line items, or form responses into your system—eliminate repetitive typing and manual review.
Standardize compliance documents
Capture regulatory or policy data from specific regions of scanned PDFs for archiving, audit, and compliance tasks.
Batch process documents at scale
Use templates to process bulk PDFs, ensuring every file is parsed with the same logic—no room for human error or inconsistency.
Classify and route incoming paperwork
Extract and use key zones to trigger routing, approvals, or next steps—integrate seamlessly with your downstream workflows.
Generate reports or summaries from PDFs
Transform extracted fields into ready-made reports—saving hours otherwise spent copying from source files.
Key features
Key features
Zone-based field mapping

Define precise extraction zones or regions on your PDFs for targeted data pull—support for structured and semi-structured documents.
Automated workflow triggers

Kick off extractions on upload, by schedule, or via API for truly hands-off document automation.
Smart text recognition and validation

OCR recognizes printed and handwritten data, with built-in checks for field types, formats, and expected patterns.
Bulk and template-based processing

Apply standardized extraction logic across batches, and easily manage templates for new document types.
No-code visual designer

Quickly annotate zones and build workflows with a drag-and-drop editor—no programming or scripting needed.
Seamless export and integration

Move data directly to Excel, databases, or business apps—plus support for PDF archiving, email, or downstream automation.
Explore all our low-code document solutions
Every team, workflow, and use case is different. Nutrient offers a proven suite of tools and integrations — built to work together and designed to help you get started fast. Pick the solution that best fits your document automation needs.
Document Converter
Convert files across formats (e.g., Excel to Word or PDF) in workflows that are fast, flexible, and fully automated.
Learn MoreDocument⠀ Editor
Enable inline editing of generated Word documents—right inside your browser, with no Word installation needed.
Learn MoreDocument Searchability
Make your generated or uploaded documents text-searchable with OCR processing and metadata enhancement.
Learn MoreDocument Automation
Deploy and manage scalable, secure document automation workflows behind your firewall or in your private cloud.
Learn MoreWhy Nutrient?

No-code simplicity
Empower operations teams to own automation.

Secure by design
Built for regulated industries and compliance.

Deep Microsoft 365 integration
Seamless workflows inside the tools you already use.

Fast time to value
Stand up solutions in days, not months.
Trusted by leading organizations






Benefits
Benefits
No need to change systems—zonal OCR slides into your current environment and feeds the data where you need it.
Automating zonal extraction removes bottlenecks, keeps business moving, and ensures rapid turnaround.
Free up staff from repetitive extraction and manual review, so they can focus on analysis or customer care.
Eliminate copy errors and ensure consistency with every extraction—ideal for audit and regulatory processes.
Process hundreds or thousands of PDFs per day without extra headcount or burnout.
The low-code interface scales with your business needs—so today’s workflow grows with tomorrow’s demand.
Automate once. Extract forever.
Turn recurring document extraction tasks into set-it-and-forget-it workflows. With Nutrient, a single setup powers every future batch—so your team stops doing the same work twice.

Connect to your tools, your way
Workflow Automation integrates with your tech stack — including finance systems, procurement platforms, and approval tools — using APIs, webhooks, or SFTP. No extra middleware required.












Frequently asked questions
Why use zonal OCR instead of standard OCR?
Standard OCR grabs all visible text. Zonal OCR is smarter — you tell it where on the page to look, so it only extracts relevant data fields. It’s ideal for structured or semi-structured documents.
Can zonal OCR be used with scanned PDFs?
Yes — zonal OCR works best when applied to scanned or image-based PDFs where key data always appears in the same location on the page.
How does Nutrient support zonal OCR?
Nutrient's SDK/API allows you to define custom zones by coordinates (x, y, width, height) and extract text only from those regions — enabling accurate, field-level automation at scale.
Can zonal OCR handle multi-page PDFs with repeating structures?
Absolutely. You can define zones once and apply them across multiple pages or documents — perfect for batch processing high volumes of forms.
What about rotated or skewed scans?
Nutrient includes pre-processing tools (like deskewing and auto-rotation) to clean up images before OCR — improving accuracy even with slightly imperfect scans.
Can I extract data and push it to a database or workflow?
Yes. Extracted fields can be returned in JSON, XML, or plain text — ready to be pushed into databases, ERP systems, or downstream workflow automations.
Start automating zonal OCR PDF workflows today
Build your first zonal extraction workflow in minutes. We’ll help you design, test, and launch PDF-to-data pipelines that replace tedious manual tasks—week after week.
.png)