




Automate key value pair extraction from PDF files
Instantly extract structured data from PDFs using easy, low-code tools. No manual retyping, no code—just accuracy, speed, and reliability.
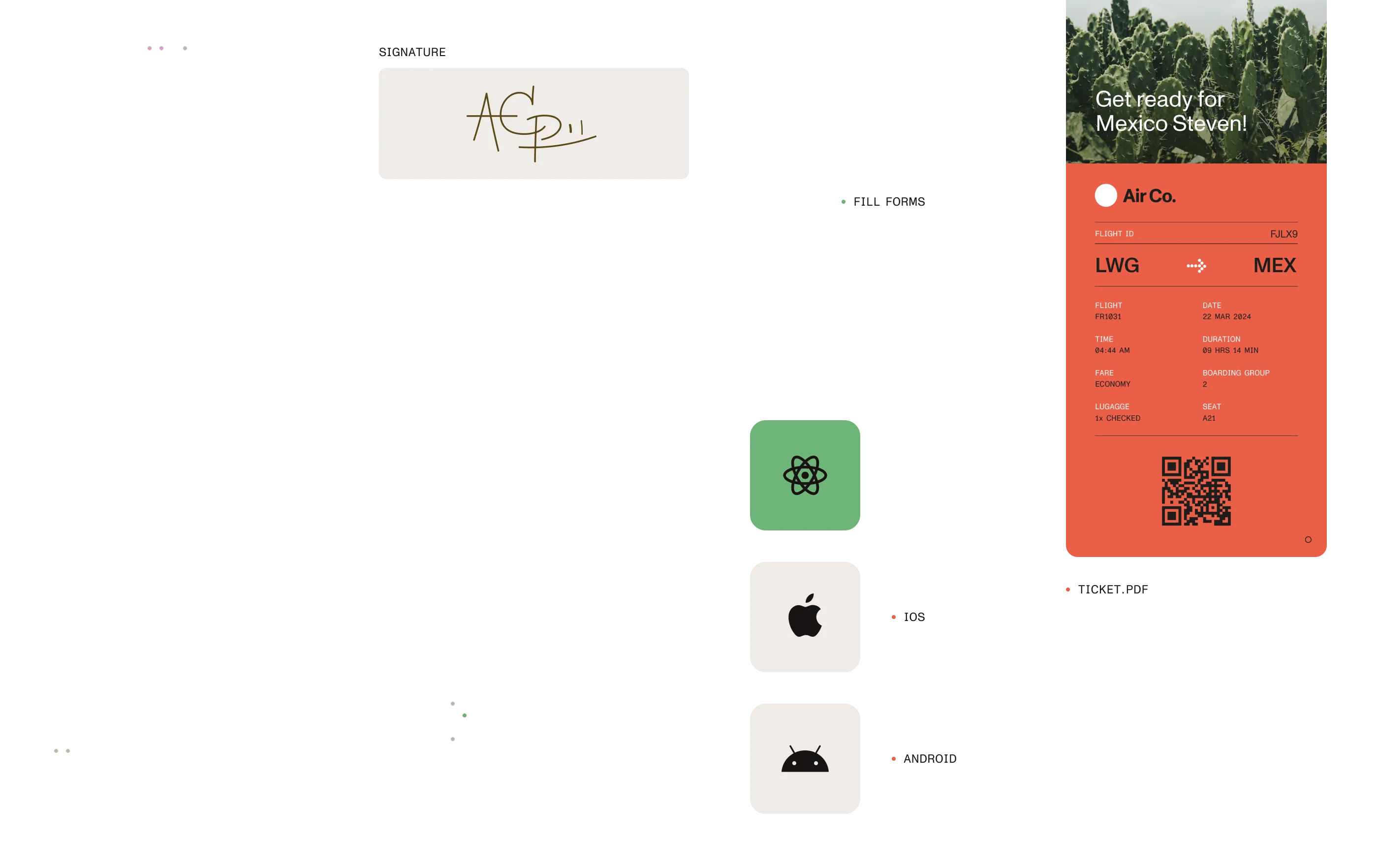

How We help
How we help
Extract data for ERP & CRM systems
Stop entering invoice, billing, or client form data by hand. Pull key values from PDFs straight into your business applications automatically—ready for workflow or analysis.
Automate onboarding document processing
Capture names, addresses, IDs, and more from application forms so you can create customer or employee records instantly with zero manual oversight.
Populate compliance databases
Extract regulatory or audit-critical fields from government forms, insurance records, or tax PDFs for submission, archiving, or reporting.
Feed extracted values to RPA workflows
Use data from PDFs to trigger robotic process automation, generate personalized documents, or fill web portals without manual copy-paste.
Process inbound PDF attachments at scale
Automate classification, routing, or ticket creation by extracting core values from bulk PDF uploads or email attachments—ideal for service desks or back-office teams.
Streamline contract review
Pull out dates, terms, and parties from legal agreements in seconds, making contract abstraction and reporting effortless and consistent.
Key features
Key features
Intelligent key value detection

Utilize advanced models to find and extract key fields from structured and semi-structured PDFs—including scanned or digital forms.
Customizable extraction templates

Map extracted values to your schema, handling variable layouts or field names with a flexible, visual template editor.
Seamless export targets

Send extracted data to databases, spreadsheets, APIs, or business systems without format conversion headaches.
Rule-based validation & transformation

Apply business rules, normalization, or formatting logic post-extraction to ensure reliability and compliance.
No-code workflow automation

Set up extraction and data delivery with an intuitive, drag-and-drop builder that connects to your existing stack.
Collaborative review and audit trail

Enable teams to validate, correct, and review extracted values in real-time with a full audit log for compliance.
Explore all our low-code document solutions
Every team, workflow, and use case is different. Nutrient offers a proven suite of tools and integrations — built to work together and designed to help you get started fast. Pick the solution that best fits your document automation needs.
Document Converter
Convert files across formats (e.g., Excel to Word or PDF) in workflows that are fast, flexible, and fully automated.
Learn MoreDocument⠀ Editor
Enable inline editing of generated Word documents—right inside your browser, with no Word installation needed.
Learn MoreDocument Searchability
Make your generated or uploaded documents text-searchable with OCR processing and metadata enhancement.
Learn MoreDocument Automation
Deploy and manage scalable, secure document automation workflows behind your firewall or in your private cloud.
Learn MoreWhy Nutrient?

No-code simplicity
Empower operations teams to own automation.

Secure by design
Built for regulated industries and compliance.

Deep Microsoft 365 integration
Seamless workflows inside the tools you already use.

Fast time to value
Stand up solutions in days, not months.
Trusted by leading organizations






Benefits
Benefits
Works directly with your current databases, APIs, and business logic, so IT doesn’t have to support new apps or workflows.
Faster cycles mean information moves where it’s needed without bottlenecks or backlogs.
Free up staff from routine data work to spend time on exceptions and real judgment calls.
Automated extraction reduces errors and creates a trail for compliance or audits.
Keep customers, partners, or regulators happy with timely, reliable data—every single time.
No need to hire for higher PDF volume. Automated extraction keeps pace with your business.
Automate once. Capture forever.
Turn recurring PDF data entry into a set-and-forget workflow. With Nutrient, extract every new key value pair—seamlessly and reliably.

Connect to your tools, your way
Workflow Automation integrates with your tech stack — including finance systems, procurement platforms, and approval tools — using APIs, webhooks, or SFTP. No extra middleware required.












Frequently asked questions
Why is key-value extraction useful?
It turns unstructured or semi-structured documents into usable data — for automation, analytics, or storage in CRMs, ERPs, or databases. No more copy-pasting from PDFs.
How does Nutrient support key-value pair extraction from PDFs?
Nutrient’s OCR and data extraction engine can identify fields based on layout, text proximity, or custom rules — returning results in structured formats like JSON or XML.
Can it work on scanned PDFs or only text-based ones?
Yes — Nutrient supports OCR-based extraction, so even scanned/image-only PDFs can be processed after applying Optical Character Recognition.
How accurate is the extraction for varying layouts?
High accuracy for fixed or template-based layouts. For variable forms, accuracy improves with custom zoning, label training, or AI-assisted field detection.
Can I define custom field labels or train it on specific forms?
Yes. You can map custom field rules, define zones (zonal OCR), or use machine learning-based training models for dynamic layout support.
What’s the ROI of automated key-value extraction?
Massive time savings, reduced errors, real-time data availability, and elimination of manual entry — especially valuable for finance, HR, insurance, and logistics operations.
Start extracting key value pairs from PDFs today
Create your first extraction workflow in minutes. We help you build, deploy, and scale PDF data extraction that replaces hours of manual data entry—week after week.
.png)