Efficiently store annotation data on Android
Depending on how you implement annotation synchronization, the storage of annotation data is managed differently.
When using Instant synchronization
When using Nutrient Instant, annotation and form data is automatically stored on Document Engine as Instant JSON, separate from the underlying PDF document. No additional work is required.
When building your own solution
We recommend storing annotation and form data separately from the underlying PDF document. By storing the data separately, you’ll only need to sync the annotation and form data to your backend, as opposed to transferring the entire PDF. Your backend can store this data as a flat file or in a database.
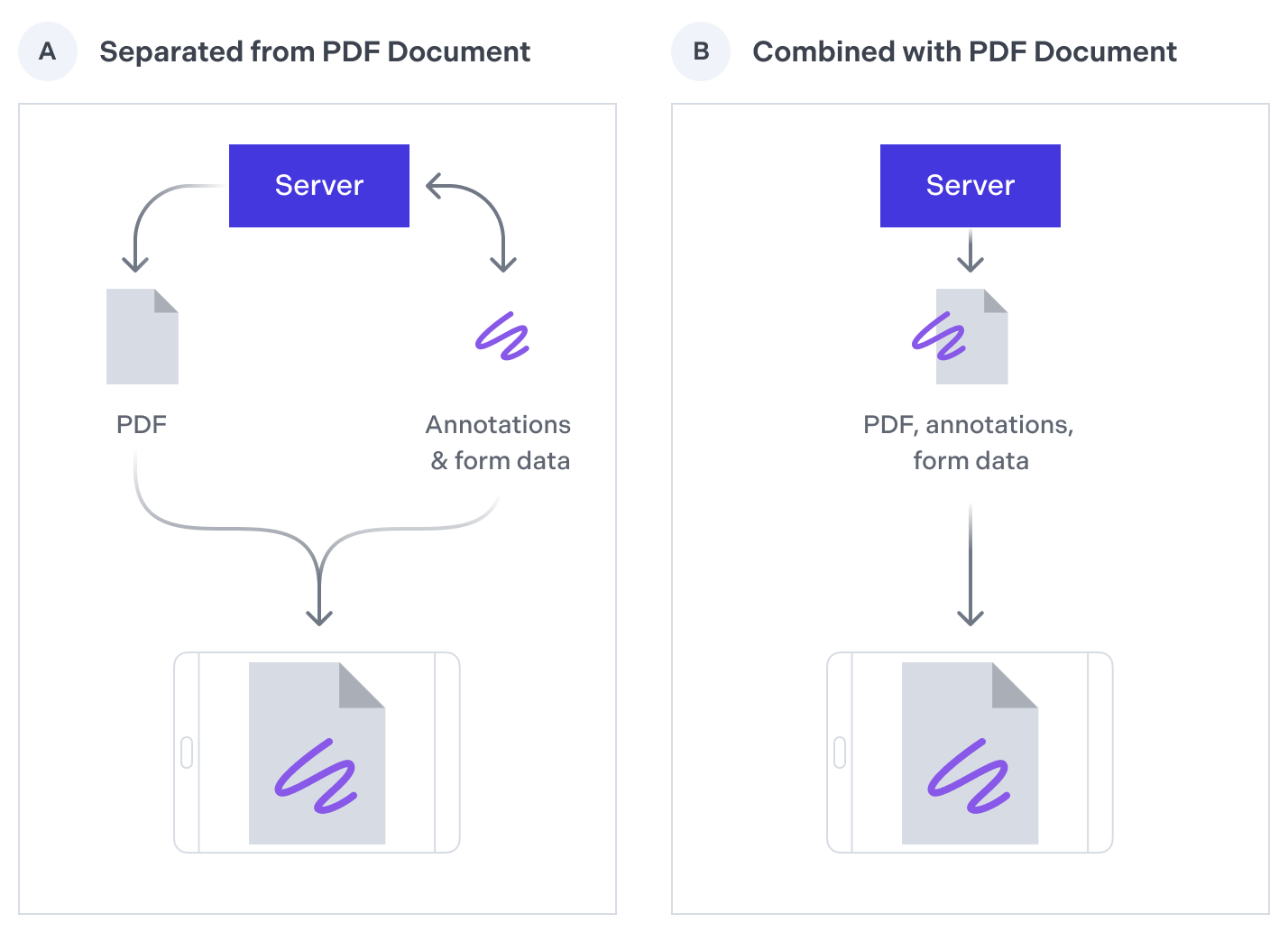
Separating the annotation and form data from the underlying PDF document has the following advantages:
- Reduced bandwidth — The PDF document is downloaded once, while smaller chunks of annotation data are synchronized to/from your server, as opposed to the entire PDF. For more information, refer to the blog on how to stop wasting bandwidth with PDFs and transfer changes with Instant JSON .
- Reduced storage — A single version of a PDF document can be stored on your server, with annotations and form data stored separately.
- Improved performance — Instead of updating and synchronizing the entire PDF document, it’s faster to create, edit, and synchronize smaller data files.
Nutrient supports importing and exporting annotations using XML Forms Data Format (XFDF) and Instant JSON. To learn more about these formats — including their benefits, limitations, and how to use them — refer to the annotation data formats guide. You can also refer to the XFDF guide or the Instant JSON guide for format-specific details.